Number of Floors Detector¶
The Number of Floors Detector uses object detection for locating floors of a building in an image input.
In general, all modern object detectors can be said to consist of three main components:
A backbone network that extracts features from the given image at different scales,
A feature network that receives multiple levels of features from the backbone and returns a list of fused features that identify the dominant features of the image,
A class and box network that takes the fused features as input to predict the class and location of each object, respectively.
EfficientDet models use EfficientNets pretrained on ImageNet for their backbone network. For the feature network, EfficienDet models use a novel bidirectional feature pyramid network (BiFPN), which takes level 3 through 7 features from the backbone network and repeatedly fuses these features in top-down and bottom-up directions. Both BiFPN layers and class/box layers are repeated multiple times with the number of repetations depending on the compund coefficient of the architecture. Fig. 1.2.15 provides and overview of the described structure. For further details please see the seminal work by Tan, Pang, and Le.
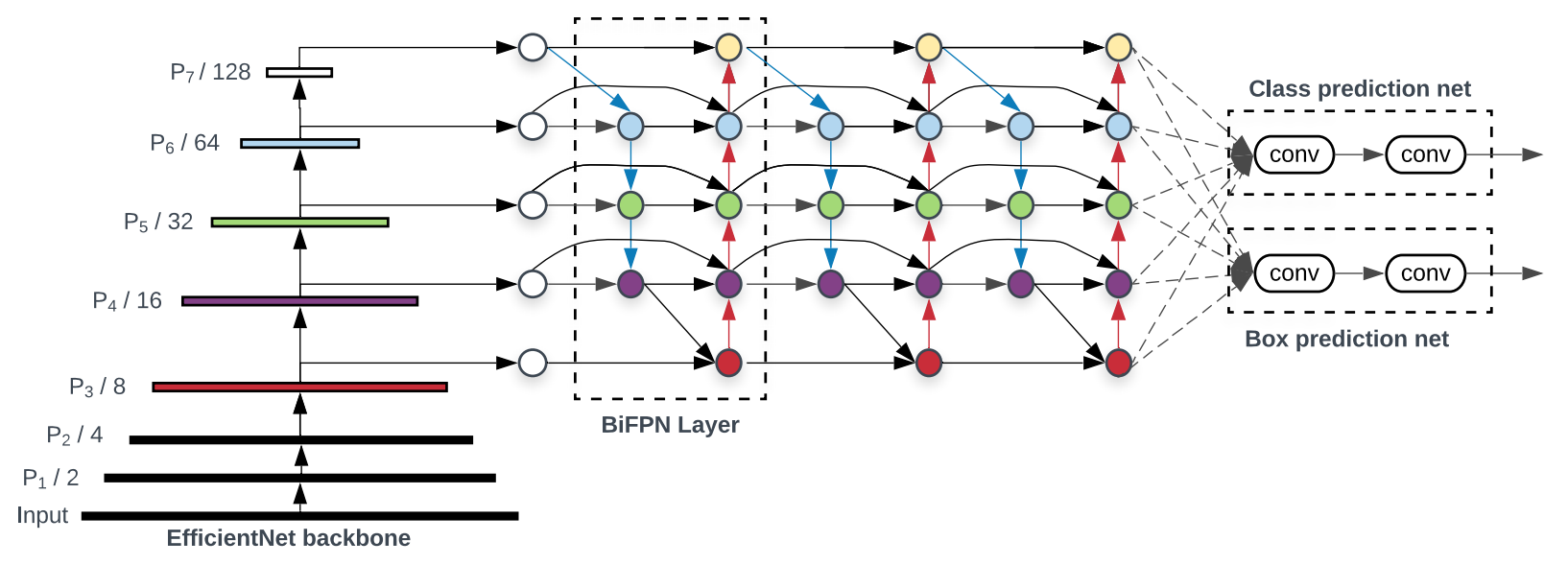
Fig. 1.2.15 A high-level representation of the EfficientDet architecture¶
Remarkable performance gains can be attained in image classification by jointly scaling up all dimensions of neural network width, depth, and input resolution, as noted in the study by Tan and Le. Inspired by this work, EfficienDet utilizes a new compound scaling method for object detection that jointly increases all dimensions of the backbone network, BiFPN, class/box network, and input image resolution, using a simple compound coefficient, φ. A total of 8 compounding levels are defined for EffcienDet, i.e., φ = 0 to 7, with EfficientDet-D0 being the simplest and EfficientDet-D7 being the most complex of the network architectures.
As shown in Fig. 1.2.16, at the time this work was published, EfficientDet object detection algorithms attained the state-of-the-art performance on the COCO dataset. Also suggested in Figure 3 is the more complex the network architecture is, the higher the detection performance will be. From a practical standpoint, however, architecture selection will depend on the availability of computational resources. For example, to train a model on an architecture with a compound coefficient higher than 4, a GPU with a memory of more than 11 GB will almost always be required.
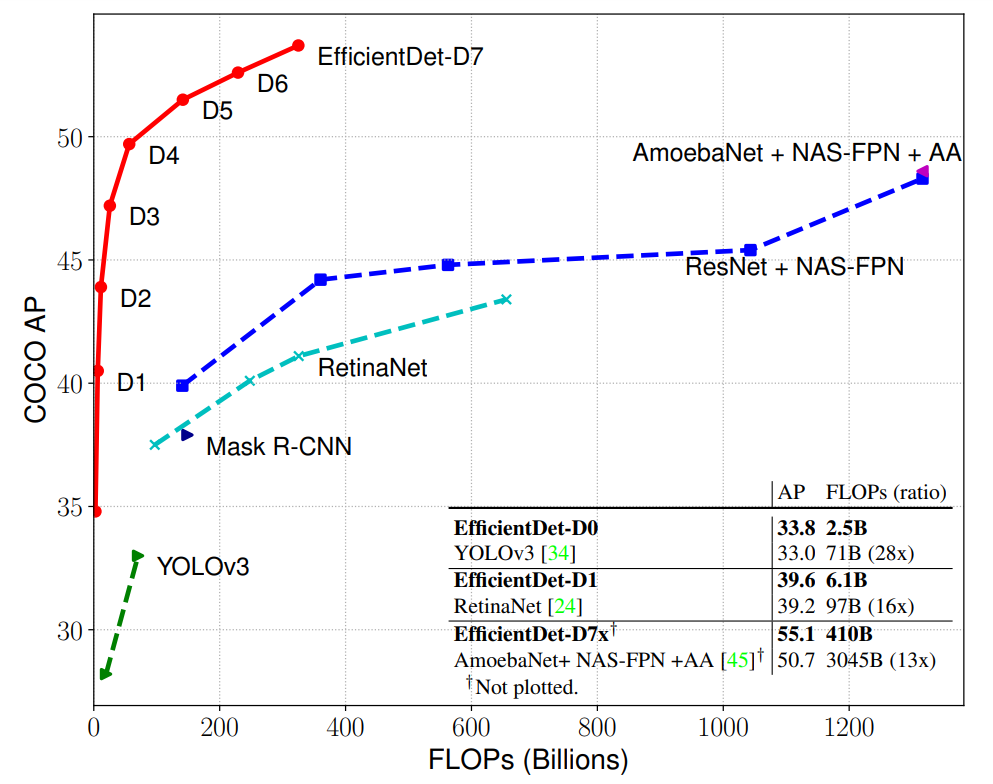
Fig. 1.2.16 A comparison of the performance and accuracy levels of EfficienDet models over other popular object detection architectures on the COCO dataset¶