2.1. Data Preperation for Training and Inference¶
2.1.1. Training Data¶
The accuracy of a deep learning model is highly dependent on the dataset used to train it. If the training data contains minimal noise and includes a sufficient level of features necessary for model development, high model prediction accuracies are attainable. In image-based applications, data noise can be in many forms, such as incorrect image labels and imagery that lack the features sought by the model (e.g., occluded features, etc.).
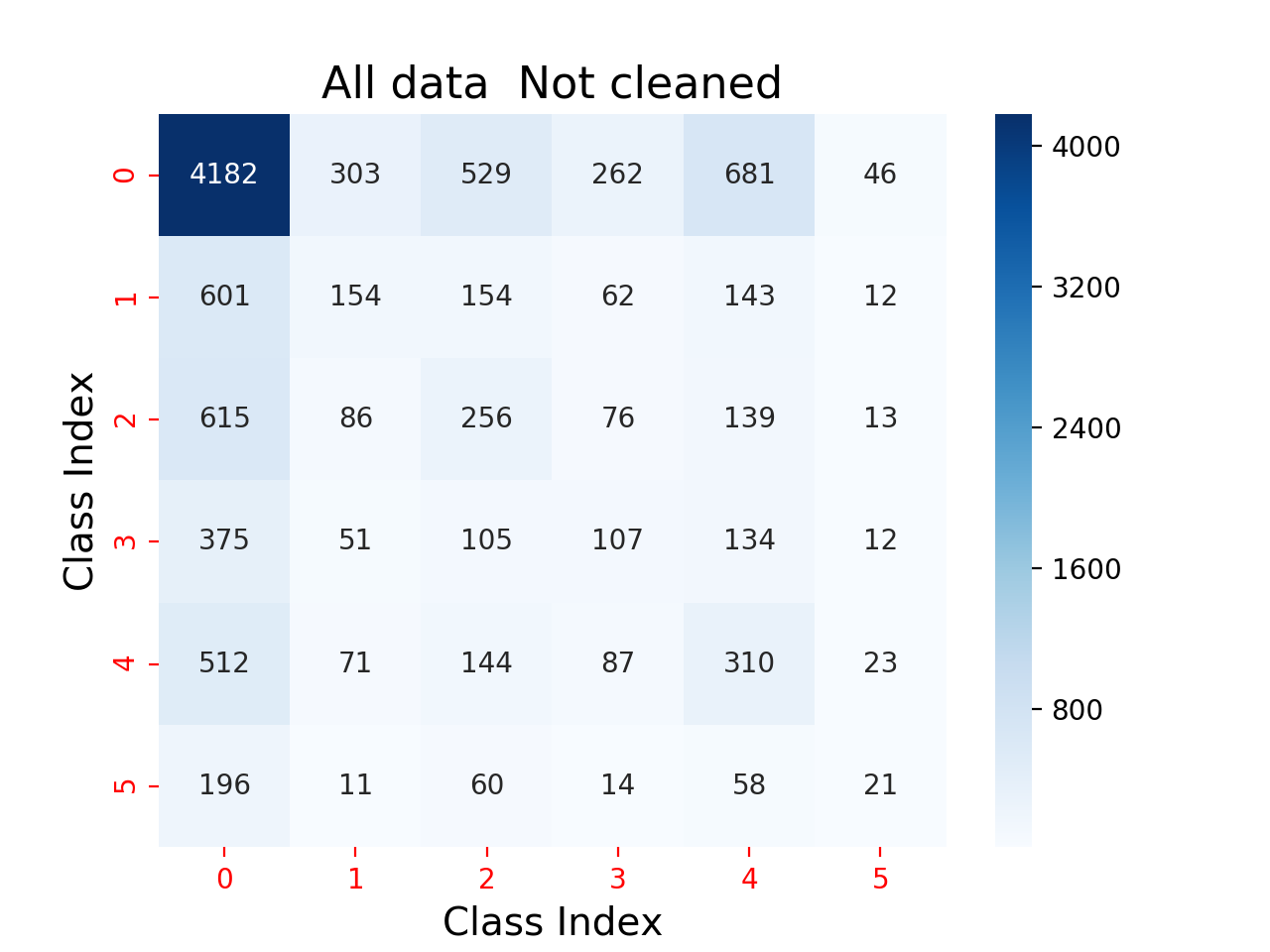
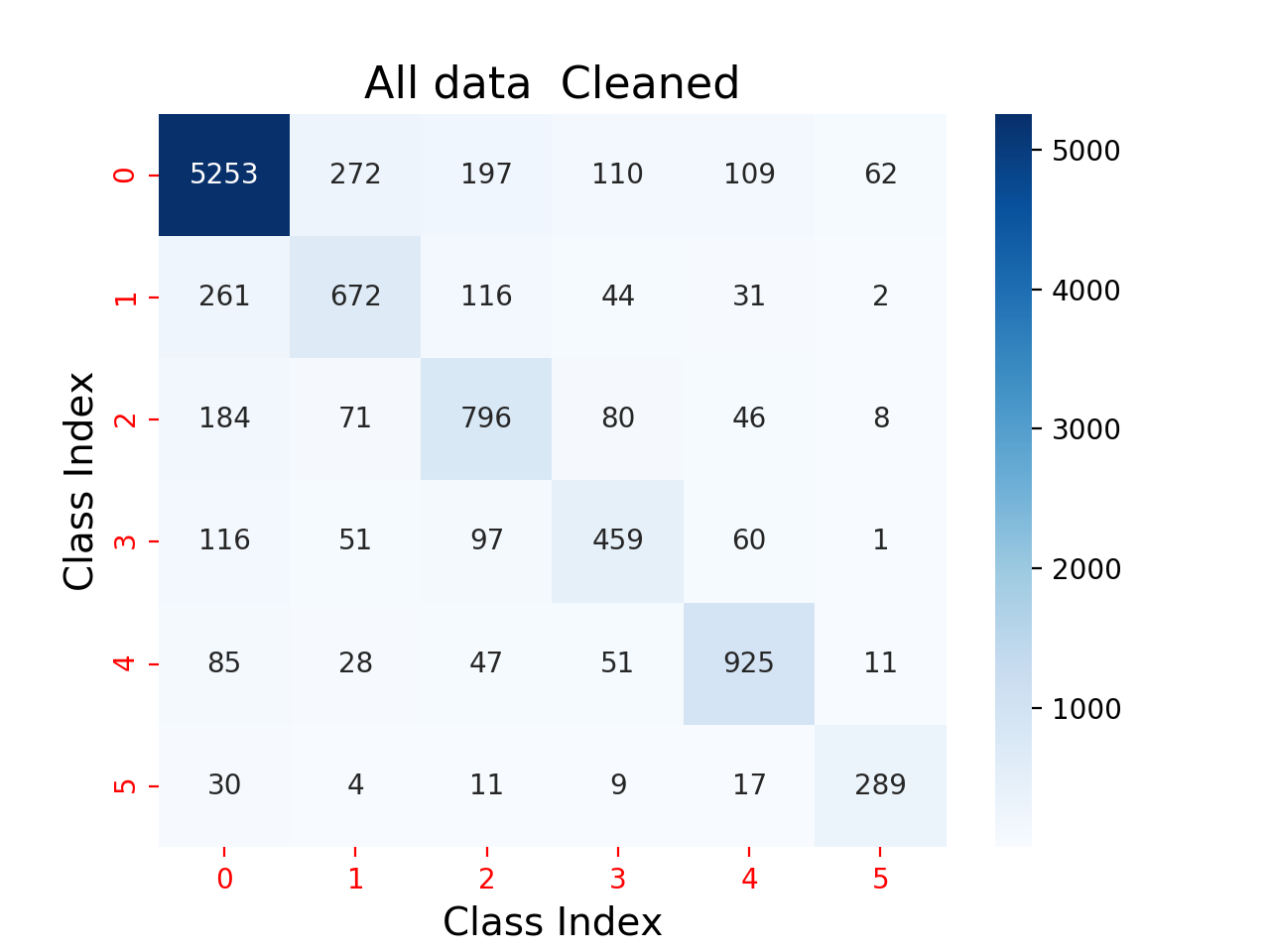
In developing the pre-trained models in BRAILS, training images are subjected to rigorous prescreening to ensure sufficient visibility of target buildings in each image in the training set. Without this screening step, creating models with reasonable confidence levels becomes difficult, since the training accuracies being inversely proportional to the extent of noise. Table 2.1.1 shows an example of one of many of our observations of this condition throughout SimCenter’s model development efforts. The confusion matrices in both figures are for models generated on identical model architecture and hyperparameters. The first confusion matrix in Table 2.1.1 is for the model trained on a dataset of images that contained 20% noisy data, while the second matrix is for the model trained on a dataset of images that were fully prescreened before model training. After 100 epochs, the former model attains an F1-score of 47.43%; the latter achieves an F1-score of 79.15% for the same validation set.
|
|
noisyImages shows a sample set of images removed after prescreening.

|

|

|

|

|

|

|

|
cleanImages shows a sample set of images that were deemed suitable for model consumption by the prescreening algorithm.

|

|

|

|

|

|

|

|
2.1.2. Data Suitable for Inference¶
For obtaining meaningful results from the models bundled with BRAILS, use of images that satisfy the following criteria is essential.
Images should contain buildings with little to no obstructions.
If possible, images should contain a single building only.
The types of buildings that the predictions are performed on should not be substantially different in appearance from the building inventories used to establish the pretrained models.
If the images used to predict building attributes meet all three criteria, attribute predictions at the accuracy levels comparable to what is reported for each module will be more achievable.