4.3. FEMA P-58 Assessment Using External Demands and REDi Recovery¶
This example is similar to Example 1 FEMA P-58 Assessment Using External Demands, with the addition of the REDi recovery step.
The file input.json contains all of the settings for this Example. It can be opened (using File/Open) to automatically populate the fields in the user interface.
The demands and the performance model for this example are based on the example building featured in FEMA P-58. More details are available in the following FEMA P-58 background documentation:

The recovery methodology in this example is based on the REDi Recovery Engine:

In this example, we are going to import demand data from simulations that were run outside of the PBE tool. This feature allows researchers to use PBE only for the performance assessment part of the workflow and connect it with any other response estimation solution they prefer to use. Because we do not need the response estimation part of the workflow for this example, we only need to focus on the DL and PRF panels in PBE.
4.3.1. DL - Asset Model¶
The first tab in the DL panel defines the asset model. The asset model assigns components to the building and defines where they are and how much of each component is at each location.
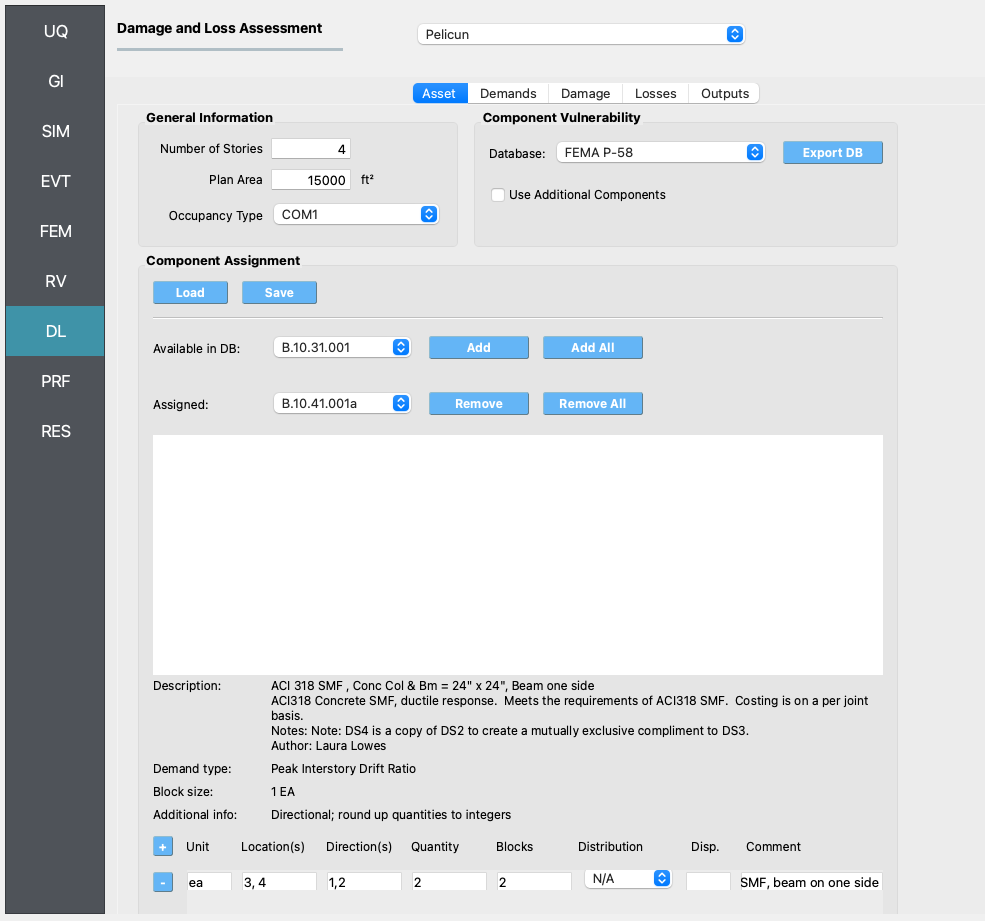
The asset model can consider uncertainties in the types of components assigned and in their quantities. This example does not introduce those uncertainties for the sake of simplicity. Consequently, for this example, the component types and their quantities are identical in all realizations.
Pelicun provides a convenience method for defining the asset model. We can prepare a table (see the figure below) where each row identifies a component and assigns some quantity of it to a set of locations and directions. Such a table can be prepared in Excel or in a text editor and saved in a CSV file - like we did in this example, see CMP_QNT.csv. Such a file is automatically created by PBE when the asset model is set up using the user interface. It can also be manually saved or the settings can be loaded from a file using the Load and Save buttons under Component Assignment Storing these models in a CSV file facilitates sharing the basic inputs of an analysis with other researchers.
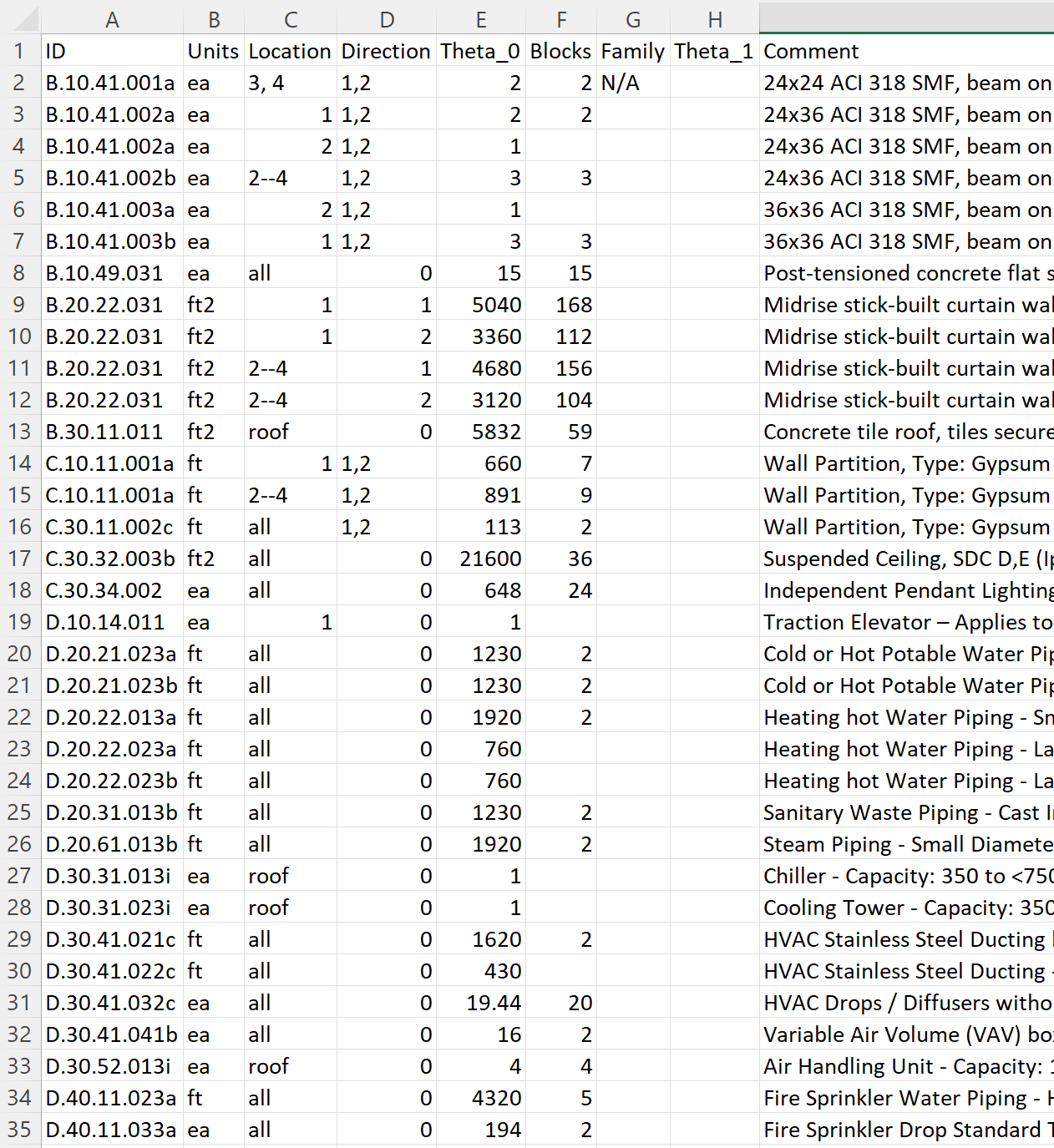
The tabular information in the csv file follows the information provided at the bottom of the Asset Model panel where the selected component is assigned to various locations and directions in the building.
We selected the built-in FEMA P-58 Component Vulnerability Database for this analysis and set the General Information features and component characteristics following the referenced example problem.
4.3.2. DL - Demand Model¶
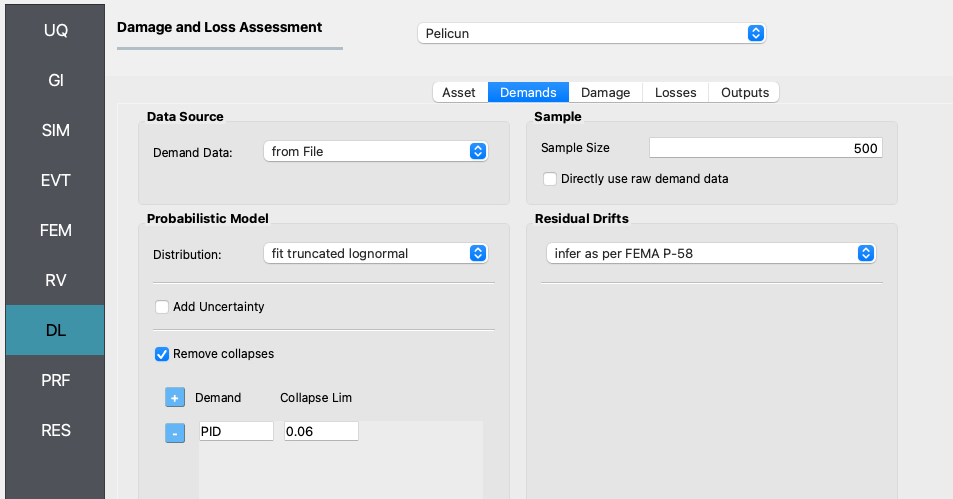
The first tab defines the demand model.Under Data Source we specified that the demands are provided in a file and specified the location of that file.
Demand distribution data was extracted from the FEMA P-58 background documentation referenced in the Introduction. The nonlinear analysis results from Figures 1-14 – 1-21 provide the 10th percentile, median, and 90th percentile of EDPs in two directions on each floor at each intensity level. We used that information to fit a lognormal distribution and sample 50 realizations of EDPs that follow the data provided for stripe #4 in the original example. The EDP data is stored in the demands_s4.csv file:
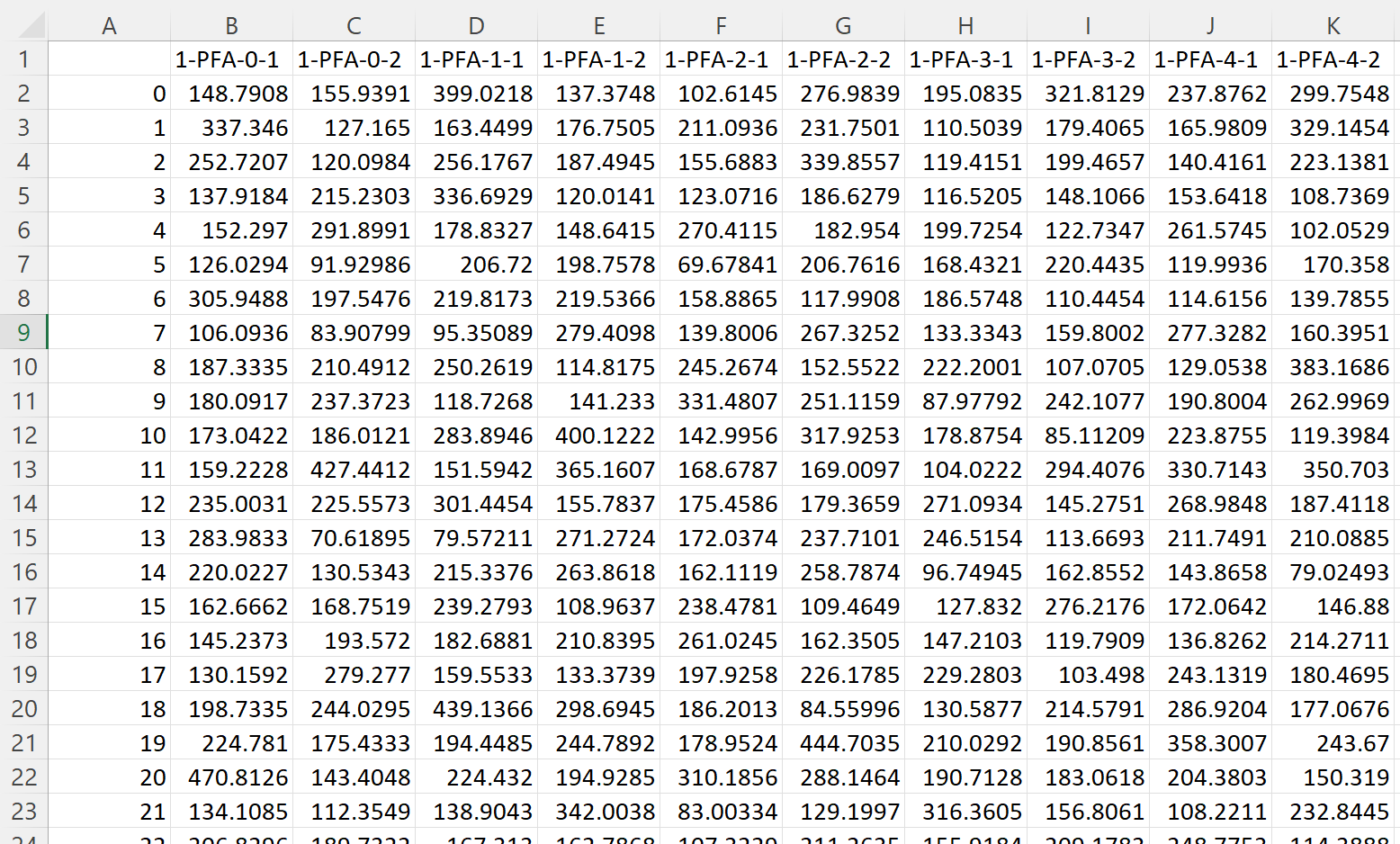
The header of the table uses the standard SimCenter demand naming convention to identify the type, location, and direction of each EDP. Each row corresponds to one realization - such data typically would come from dynamic analysis.
One the demands are imported, the settings in the panel instruct Pelicun to fit a truncated lognormal distribution to the data considering everything above a peak interstory drift (PID) of 6% as collapsed cases. Then, sample the fitted multivariate distribution to get 500 demand realizations and use the methodology from FEMA P-58 to infer residual drifts based on PID values.
4.3.3. DL - Damage Model¶
We have already identified the components in the buildings and the component database includes the fragility functions that characterize component vulnerabilities through probabilistic capacities corresponding to various limit states.
We use the Damage Model tab to extend the above dataset with two Global Vulnerabilities: Irreparable Damage and Collapse.
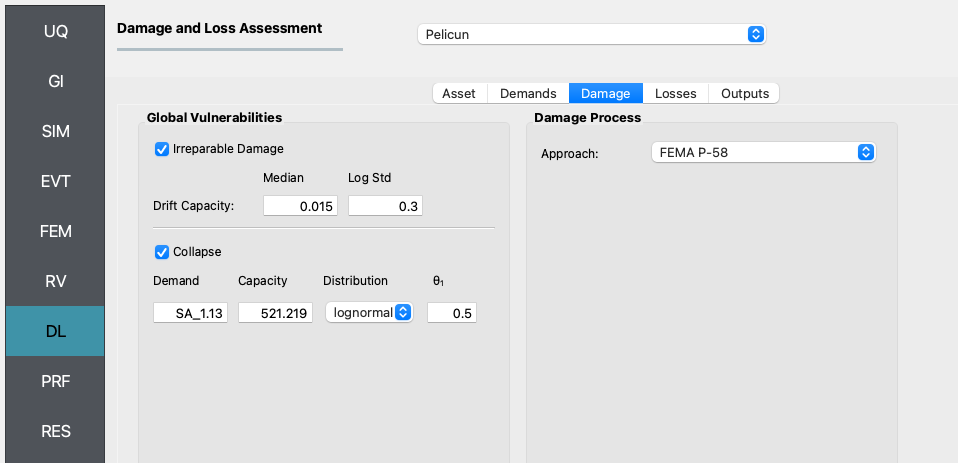
Irreparable damage is triggered when the residual drift of any story in the structure exceeds a pre-defined threshold. We use the recommended values from FEMA P-58 for that threshold here.
Following the typical approach in FEMA P-58 performance assessment, the collapse limit state is characterized by a collapse fragility function. The controlling variable is an IM, the spectral acceleration at T1=1.13 s. Given the multi-stripe setup of the example problem, all realizations at one stripe have the same Sa(T1) value. This value is added for every realization using an extra column in the demands_s4.csv file. The capacity, distribution, and theta_1 parameters are used to define the lognormal fragility function. Note that the capacity is provided in inches/s2 because the length unit for the analysis in the GI panel is set to inches.
We use the built-in FEMA P-58 damage process for this example.
4.3.4. DL - Loss Model¶
Consequence modeling is decoupled from damage modeling in Pelicun. The Loss Model tab is used to identify the consequence database for each type of consequence we would like to include in the analysis and map the consequence models to the damaged components. This process is trivial if one wants to follow the FEMA P-58 methodology and the mapping is performed automatically by the PBE tool.
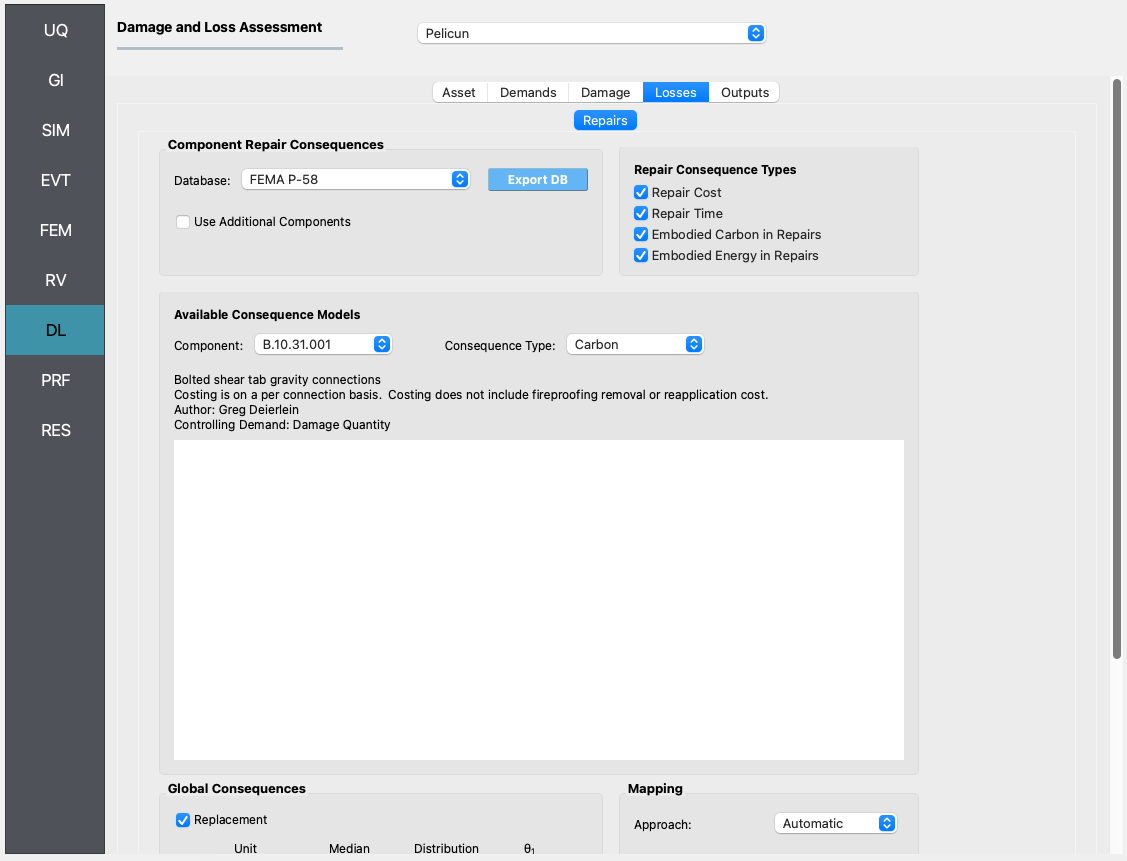
We use this panel to add a replacement consequence to the FEMA P-58 dataset. This defines a replacement cost and time and the automatic mapping links these consequences with the collapse and irreparable damage events. Note that the replacement consequences are defined using random variables in this example to capture the uncertainty in those numbers. The deterministic replacement values that FEMA P-58 uses can be reproduced in PBE by choosing N/A for the Distribution of Cost and Time.
4.3.5. PRF - Recovery¶
For the recovery performance assessment, the REDi Recovery Engine is employed.
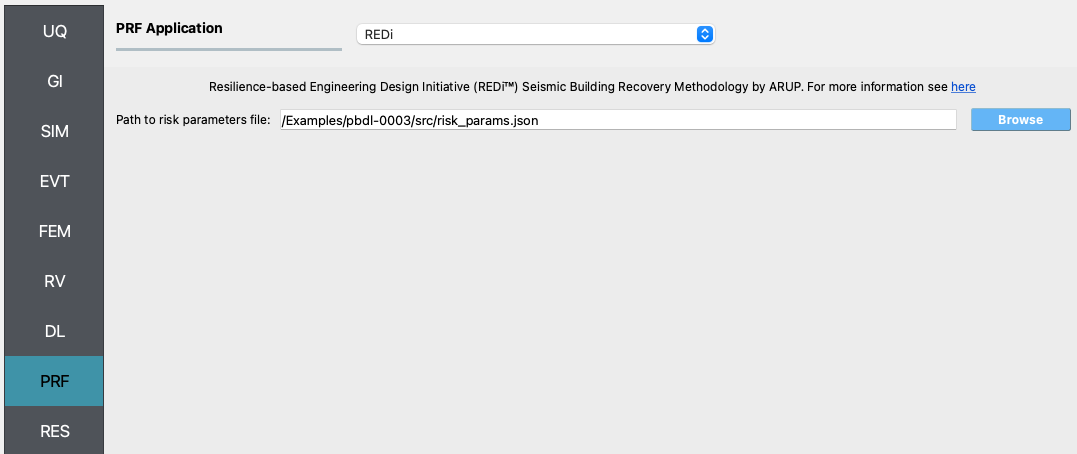
The only input is the risk parameters json file. The risk parameters file is a json file that contains the necessary inputs required by the REDi engine. Example risk parameters include impeding factors such as permit delay time. For a full list and an explanation of the required risk parameters, see the Risk Parameters section in the REDi documentation.
4.3.6. Analysis & Results¶
Once the performance assessment has been set up, click on the Run button. When the analysis is complete the RES tab will be activated and the results will be displayed. The Summary and Data tabs of the results panel are shown below. Since we are running the REDi recovery assessment in addition to the damage and loss, you will see the REDi Recovery section appear below the DL values.
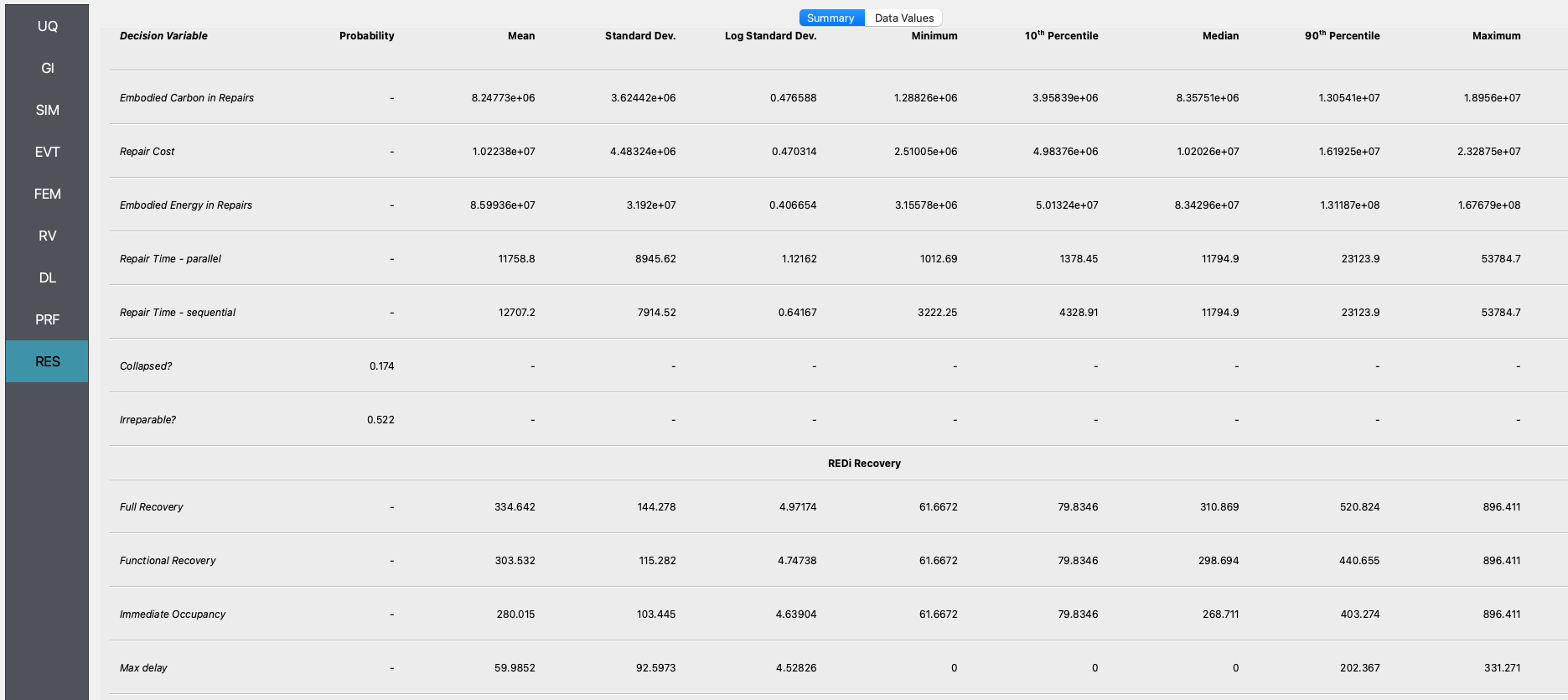
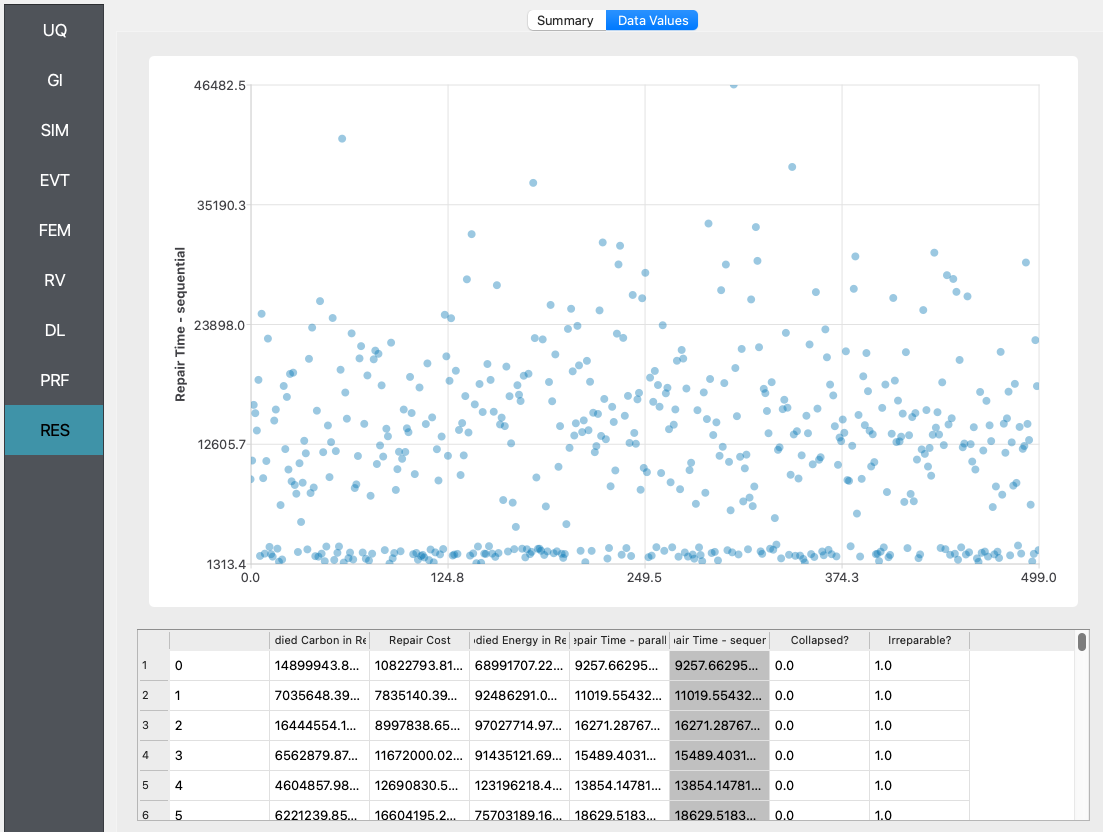
In the Data tab of the RES panel, we are presented with both a graphical plot and a tabular listing of the data. By left- and right-clicking on the individual columns the plot axis changes (left mouse click controls vertical axis, right mouse click the horizontal axis). If a singular column of the tabular data is selected with both right and left mouse buttons, a frequency and CDF plot will be displayed.