Methods in UCSD UQ Engine
Transitional Markov chain Monte Carlo
TMCMC is a numerical method used to obtain samples of the target posterior PDF. This algorithm is flexible, applicable in general settings, and parallelizable. Thus, it can be used to effectively sample the posterior PDF, when the likelihood function involves an FE model evaluation, using high-performance computing (HPC) resources.
In Bayesian inference, the posterior probability distribution of the unknown quantities, represented by the vector \(\mathbf{\theta}\), is obtained by applying Bayes’ rule as follows:
The idea behind TMCMC is to avoid sampling directly from the target posterior PDF \(p(\mathbf{\theta \ | \ y})\), but to sample from a series of simpler intermediate probability distributions that converge to the target posterior PDF. To achieve this, the TMCMC sampler proceeds through a series of stages, starting from the prior PDF until the posterior PDF. These intermediate probability distributions (called tempered posterior PDFs) are controlled by the tempering parameter \(\beta_j\) as
Index \(j\) denotes the stage number, \(m\) denotes the total number of stages, and \(p (\mathbf{\theta \ | \ y})_j\) is the tempered posterior PDF at stage \(j\) controlled by the parameter \(\beta_j\). At the initial stage \((j = 0)\), parameter \(\beta_0 = 0\), the tempered distribution \(p(\mathbf{\theta \ | \ y})_{j=0}\) is just the prior joint PDF \(p(\theta)\). The TMCMC sampler progresses by monotonically increasing the value of \(\beta_j\), at each stage \(j\), until it reaches the value of 1. At the final stage \((j = m)\), parameter \(\beta_m = 1\), the tempered distribution \(p(\mathbf{\theta \ | \ y})_{j = m}\) is the target posterior joint PDF \(p(\mathbf{\theta \ | \ y})\).
TMCMC represents the tempered posterior PDF at every stage by a set of weighted samples (known as particles). TMCMC approximates the \(j^{th}\) stage tempered posterior PDF \(p(\mathbf{\theta \ | \ y})_j\) by weighing, resampling, and perturbing the particles of the \(j-1^{th}\) stage intermediate joint PDF \(p(\mathbf{\theta \ | \ y})_{j-1}\). For details about the TMCMC algorithm, the interested reader is referred to Ching and Chen [Ching2007], Minson et. al. [Minson2013].
Ching and Y.-C. Chen, “Transitional Markov Chain Monte Carlo Method for Bayesian Model Updating, Model Class Selection, and Model Averaging”, Journal of Engineering Mechanics, 133(7), 816-832, 2007.
Minson, M. Simons, and J. L. Beck, “Bayesian Inversion for Finite Fault Earthquake Source Models I-Theory and Algorithm”, Geophysical Journal International, 194(3), 1701- 1726, 2013.
Gaussian Process-Aided Bayesian Calibration (GP-AB)
The GP-AB algorithm [Taflanidis2025] is a surrogate-aided extension of the Transitional Markov Chain Monte Carlo (Transitional Markov chain Monte Carlo) sampling method. It is designed for Bayesian updating problems in which evaluating the likelihood function \(L_D(\theta, q)\) requires computationally expensive finite element (FE) simulations. By replacing these simulations with predictions from a Gaussian Process (GP) surrogate model, GP-AB can significantly reduce the computational cost of posterior sampling while still converging to the same posterior distribution obtained if the original FE model was used.
In GP-AB, the GP surrogate is developed and adaptively refined in an iterative process using a design of experiments (DoE) strategy that balances exploitation (focusing on regions of high posterior probability) and exploration (sampling previously under-explored regions). This adaptive refinement continues until the surrogate-based posterior converges according to specified criteria described in the following sections.
Formulation of the Bayesian Calibration Problem
Consider a model with unknown parameters \(\theta \in \mathbb{R}^{n_\theta}\) and prediction error parameters \(q \in \mathbb{R}^{n_q}\), where \(n_\theta\) and \(n_q\) denote their respective dimensions. Let \(D\) denote the available input-output data, consisting of measured system outputs \(\hat{\mathbf{y}}\) for known inputs \(\hat{\mathbf{u}}\).
The posterior probability density function (PDF) is given by Bayes’ rule:
where \(L_D(\theta, q)\) is the likelihood of the data given the parameters, and \(p(\theta)\) and \(p(q)\) are the prior PDFs.
The target posterior \(p(\theta, q \,|\, D)\) is approximated using TMCMC, but instead of evaluating the expensive model response \(\mathbf{y}(\theta|\mathbf{u})\) at every sample, GP-AB builds a GP surrogate that predicts this response accurately in the regions of interest.
Likelihood Function
In the quoFEM implementation, a Gaussian likelihood is used, with unknown error variances. Assigning a Jeffreys prior \(p(q) \propto 1/q\) to the unknown variance yields a closed-form likelihood in terms of the model parameters \(\theta\) only.
Let \(z(\theta) \in \mathbb{R}^{n_z}\) be the stacked vector of all model outputs for the observation cases in \(D\), and \(\hat{z}\) the corresponding stacked measurements. The residual vector is:
The resulting marginalized likelihood is:
where \(n_D = n_z\) is the total number of scalar observations.
Surrogate Model Formulation
The surrogate is built for the vectorized model response:
where \(Y_D(\theta)\) stacks the model outputs for all observation cases in \(D\), and \(n_z = n_y \, n_D\) is the total number of output components.
Because \(n_z\) can be large, Principal Component Analysis (PCA) is used to reduce the output dimension before GP training. Let \(\{ v_q \}_{q=1}^{n_v}\) be the retained principal component (PC) scores, chosen so that a prescribed fraction \(r_{pc}\) of the variance in the training outputs is preserved. A separate GP metamodel is calibrated for each PC score:
where \(\tilde{v}_q(\theta)\) and \(\sigma_{v_q}^2(\theta)\) are the GP-predicted mean and variance, respectively. The predicted model response is reconstructed as:
with \(\mu_z\) the mean output vector from training data, \(P\) the PCA projection matrix, and \(\tilde{\mathbf{v}}(\theta)\) the vector of GP-predicted PC scores.
The GP-predicted response \(\tilde{z}(\theta)\) is then used in place of \(z(\theta)\) when evaluating the likelihood and posterior.
Adaptive Design of Experiments (DoE)
At each iteration \(k\), the surrogate is improved by adding \(2 * {n_\theta}\) new training points. Candidate points are chosen using the weighted integrated mean squared error (IMSE) acquisition function:
where:
\(\Theta_d\) is the parameter domain,
\(\phi(\theta)\) is a weight function prioritizing important regions,
\(\hat{\sigma}^2\) is the average GP predictive variance across all output components after adding \(\theta_\text{new}\),
\(s^{*(k)}\) are the optimized GP hyperparameters at iteration \(k\).
Weight function: \(\phi(\theta)\) is a convex combination of the GP-approximated target posterior and some intermediate TMCMC densities from the current iteration:
This balances exploitation of the high-probability posterior regions with exploration along the TMCMC path from prior to posterior. \(j^*\) is defined in the following section on warm-starting TMCMC, and \(j_t\) is the total number of stages in the current iteration.
A fraction of the new points is selected purely for exploration by setting \(\phi(\theta) \equiv 1\).
Convergence Assessment
Convergence of the surrogate-based posterior is tested between consecutive iterations using a dimension-normalized KL divergence:
()\[g^{(k)}_{\mathrm{KL}} = \frac{1}{n_\theta} \ \mathrm{KL}\!\left( \tilde{\pi}^{(k)}(\theta) \ \big\| \ \tilde{\pi}^{(k-1)}(\theta) \right)\]where the KL divergence is estimated by importance sampling using the TMCMC samples.
An optional LOOCV error metric \(g^{(k)}_{\mathrm{CV}}\) can be used to assess GP predictive accuracy independently of the posterior approximation.
If \(g_{\mathrm{KL}} < c_{\mathrm{KL}}\) and \(g_{\mathrm{CV}} < c_{\mathrm{CV}}\), the algorithm stops.
Warm-Start TMCMC
If the LOOCV error \(g_{\mathrm{CV}}\) is below a threshold, TMCMC can be warm-started at a later stage \(j^*\) by reweighting samples from the same stage of the previous iteration, avoiding re-sampling from the prior. The stage \(j^*\) is chosen such that the coefficient of variation of these weights is below a specified limit.
Algorithm Summary
The GP-AB algorithm proceeds as follows:
Initialization: - Select initial training points in \(\Theta_d\) via a space-filling design. - Evaluate the high-fidelity model at these points and build the initial PCA+GP surrogate.
Posterior Approximation: - Use the GP surrogate to evaluate \(\tilde{L}^{(k)}_D(\theta, q)\) and run TMCMC (warm-start if possible) to sample the posterior.
Convergence Check: - Compute \(g_{\mathrm{KL}}\). - If it is below a threshold (0.001), stop.
Adaptive DoE: - Select \(\lceil r_{\mathrm{ex}} * {2*n_\theta} \rceil\) exploitation points using weighted IMSE. - Select the remainder for exploration. - Run high-fidelity simulations at new points, update the surrogate, and increment \(k\).
Repeat steps 2-4 until convergence or computational budget is reached.
Remarks
GP-AB focuses GP refinement on regions relevant to the posterior, improving efficiency over space-filling designs.
The balance between exploitation and exploration controls robustness: more exploration is promoted automatically during the initial iterations of GP-AB to reduce the risk of missing important regions.
Warm-starting TMCMC can further reduce sampling cost when surrogates are accurate.
A.A. Taflanidis, B.S. Aakash, S.R. Yi, and J.P. Conte, “Surrogate-aided Bayesian calibration with adaptive learning strategies”, Mechanical Systems and Signal Processing, 237, 113014, 2025. https://doi.org/10.1016/j.ymssp.2025.113014
Bayesian Inference of Hierarchical Models
Consider for model calibration a dataset consisting of experimental results on test specimens of the same kind. Let \(\mathbf{y}_i\) denote the measured output response of the \(i^{th}\) specimen in the dataset \(\mathbf{Y} = \{\mathbf{y}_1, \mathbf{y}_2, ..., \mathbf{y}_{N_s}\}\) where \(N_s\) designates the number of specimens. Let \(\theta_i\) be the model parameter vector corresponding to the \(i^{th}\) specimen, where \(n_\theta\) denotes the number of model parameters. For the \(i^{th}\) specimen, the output response \(\mathbf{y}_i\) can be viewed as a function of \(\theta_i\) through the model \(\mathbf{h}\) and the following measurement equation:
where \(\mathbf{w}_i\) denotes the discrepancy between the response predicted by the model parameterized with \(\theta_i\), i.e., \(\mathbf{h}(\theta_i)\), and the experimental output response \(\mathbf{y}_i\); \(\mathbf{w}_i\) is termed the prediction error. With the measurement equation in (), the sources of real-world uncertainties such as the measurement noise during data collection and model form error are lumped and accounted for in the prediction error (also called noise) term \(\mathbf{w}_i\) (i.e., \(\mathbf{w}_i\) is also a proxy for model form error). In quoFEM, it is assumed that the prediction error is a zero-mean Gaussian white noise, thus,
where \(\sigma_i^2\) denotes the variance of the prediction error \(\mathbf{w}_i\).
With the assumptions made in () and (), \(\mathbf{y}_i\) is Gaussian and centered at the model response \(\mathbf{h}(\theta_i)\), with a diagonal covariance matrix equal to \(\sigma_i^2 \times \mathbf{I}_{n_{\mathbf{y}_i} \times n_{\mathbf{y}_i}}\) i.e.,
In the UCSD_UQ engine, hierarchical Bayesian modeling is used to account for specimen-to-specimen variability in the parameter estimates. In the hierarchical Bayesian modeling realm, the parameter vectors \(\theta_1, \theta_2, \ldots, \theta_{N_s}\) are considered as mutually statistically independent and identically distributed (s.i.i.d) random variables following a PDF \(p(\theta | \eta)\). This is the PDF of the parent distribution, which represents the aleatory specimen-to-specimen variability.
The objective of hierarchical Bayesian inference is to jointly estimate the model parameters \(\theta_i\) for each specimen i (along with its prediction error variance \(\sigma_i^2\)) as well as the hyperparameters \(\eta\) of the parent distribution of the set \(\theta_i (i = 1, \ldots, N_s)\).
Making use of the experimental results for a single specimen, \(\mathbf{y}_i\), Bayes’ theorem for all parameters to be inferred from this specimen can be written as
The specimen response \(\mathbf{y}_i\) depends solely on the model parameters \(\theta_i\) and the prediction error variance for that specimen, \(\sigma_i^2\), and is independent of the hyperparameters \(\eta\). Consequently, the conditional PDF \(p(\mathbf{y}_i | \theta_i, \sigma_i^2, \eta)\) reduces to \(p(\mathbf{y}_i | \theta_i, \sigma_i^2)\).
Assuming \(\sigma_i^2\) to be statistically independent of \(\theta_i\) and \(\eta\) in the joint prior PDF of \(\theta_i\), \(\sigma_i^2\), and \(\eta\), () becomes
In the context of hierarchical Bayesian modeling, the entire experimental dataset from multiple specimens of the same kind, \(\mathbf{Y} = \{\mathbf{y}_1, \mathbf{y}_2, ..., \mathbf{y}_{N_s}\}\), is considered. The model parameters and the prediction error variances for all specimens are assumed to be mutually statistically independent, while the set of model parameter estimates are assumed to be samples from a parent distribution. The figure figHierarchicalModel shows the structure of the hierarchical model.
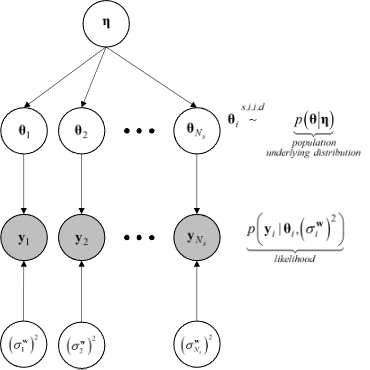
Structure of the hierarchical model
Under these assumptions, the equation for Bayesian updating of all unknown quantities in the hierarchical model, including the model parameters \(\Theta = \{\theta_1, \theta_2, \ldots, \theta_{N_s}\}\), measurement noise variances \(\mathbf{s} = \{\sigma_1^2, \sigma_2^2, \ldots, \sigma_{N_s}^2\}\), and hyperparameters \(\eta\) is given by
The marginal posterior distribution of the hyperparameters, \(p(\eta | \mathbf{Y})\) , is obtained by marginalizing out \(\mathbf{\Theta}\) and \(\mathbf{s}\) from \(p(\Theta, \mathbf{s}, \eta | \mathbf{Y})\) as
The distribution \(p(\eta | \mathbf{Y})\) describes the epistemic uncertainty in the value of the hyperparameters \(\eta\) due to the finite number of specimens \(N_s\) in the experimental dataset.
In the hierarchical approach, the probability distribution of the model parameters conditioned on the entire measurement dataset, \(p(\theta | \mathbf{Y})\), is given by
The conditional distribution \(p(\theta | \eta)\) models the aleatory specimen-to-specimen variability. Therefore, the probability distribution \(p(\theta | \mathbf{Y})\), referred to as the posterior predictive distribution of the model parameters \(\theta\), encompasses both the aleatory specimen-to-specimen uncertainty and the epistemic estimation uncertainty (due to the finite number of specimens \(N_s\) in the experimental dataset and the finite length of the experimental data corresponding to each specimen). It can be utilized for uncertainty quantification and propagation in reliability and risk analyses.
Special Case: Normal Population Distribution
The hierarchical modeling approach discussed above captures the specimen-to-specimen aleatory variability by modeling the model parameters corresponding to each experiment as a realization from a population distribution. In the UCSD_UQ engine, a multivariate normal distribution \(\theta | \eta \sim N (\mu_\theta, \Sigma_\theta)\) is adopted (i.e., \(\eta = (\mu_\theta, \Sigma_\theta)\)) as:
In the Bayesian inference process, the hyperparameters characterizing the population probability distribution, the hypermean vector \(\mu_\theta\) and the hypercovariance matrix \(\Sigma_\theta\) are jointly estimated with all the \(\theta_i\) s and \(\sigma_i^2\) s.
So, for this special case, () becomes
with \(\Theta\), \(\mathbf{Y}\), and \(\mathbf{s}\) as defined above.
In the UCSD_UQ engine, the sampling algorithm operates in the standard normal space i.e.,
and the Nataf transform is utilized to map the values provided by the sampling algorithm to the physical space of the model parameters before the model is evaluated.
Sampling the Posterior Probability Distribution of the Parameters of the Hierarchical Model
Due to the high dimensionality (\(n_\theta \times n_s + n_s + n_\theta + n_\theta \times \frac{(n_\theta+1)}{2}\), corresponding to the dimensions of the \(\theta_i\) of each dataset, \(\sigma_i^2\) for each dataset, \(\mu_\theta\) and \(\Sigma_\theta\), respectively) of the posterior joint PDF shown in (), the Metropolis within Gibbs algorithm is used to generate samples from the posterior probability distribution. To do this, conditional posterior distributions are derived for blocks of parameters from the joint posterior distribution () of all the parameters of the hierarchical model. The Gibbs sampler generates values from these conditional posterior distributions iteratively. The conditional posterior distributions are lower dimensional than the joint distribution. The assumptions made next result in a few of the conditional posterior distributions being of a form that can be easily sampled from, thereby making it feasible to draw samples from the high-dimensional joint posterior PDF of the hierarchical model.
The prior distributions for each \(\sigma_i^2\) are selected as the inverse gamma (IG) distribution:
The prior probability distribution for \((\mu_\theta, \Sigma_\theta)\) is chosen to be the normal-inverse-Wishart (NIW) distribution:
With these assumptions, the conditional posterior distributions are the following:
where:
and,
The Metropolis within Gibbs sampler generates values from the posterior joint PDF shown in () using the posterior conditional distributions () through the following steps:
Select appropriate initial values for each of the \(\theta_i\).
Based on the \(k^{th}\) sample value, the \((k+1)^{th}\) sample value is obtained using the following steps:
Generate a sample value of \(\Sigma_{\theta}^{(k+1)}\) from the conditional posterior distribution \(IW(\Sigma_n, m_n)\)
Generate a sample value of \(\mu_\theta^{(k+1)}\) from the conditional posterior distribution \(N(\mu_n, \frac{\Sigma_\theta}{\nu_n})\)
For each dataset, generate independently a sample value of \(\sigma_i^{2(k+1)}\) from the conditional posterior distribution of each \(\sigma_i^2\): \(IG(\alpha_n, \beta_n)\)
For each dataset, generate a sample value of the model parameters \(\theta_i\) from the conditional posterior \(p(\mathbf{y}_i | \theta_i, \sigma_i^2) p(\theta_i | \mu_\theta, \Sigma_\theta)\) with a Metropolis-Hastings step as follows:
Generate a candidate sample \(\theta_{i(c)}\) from a local random walk proposal density \(\theta_{i(c)} \sim N(\theta_i^{(k)}, \Sigma_i^{(k)})\) where \(\Sigma_i^{(k)}\) is the proposal covariance matrix of the random walk.
Calculate the acceptance ratio
()\[a_c = \frac{p(\mathbf{y}_i | \theta_{i(c)}, \sigma_i^{2(k+1)}) p(\theta_{i(c)} | \mu_\theta^{(k+1)}, \Sigma_{\theta}^{(k+1)})}{p(\mathbf{y}_i | \theta_i^{(k)}, \sigma_i^{2(k+1)}) p(\theta_i^{(k)}| \mu_\theta^{(k+1)}, \Sigma_{\theta}^{(k+1)})}\]Generate a random value \(u\) from a uniform distribution on [0, 1] and set
()\[\begin{split}\theta_i^{(k+1)} = \quad &\theta_{i(c)} \quad \text{if} \quad u < a_c \\ &\theta_i^{(k)} \quad \text{otherwise}\end{split}\]
After an initial burn-in period, the sample values generated by this algorithm converge to the target density. The proposal covariance matrix of the random walk \(\Sigma_i^{(k)}\) is selected to facilitate proper mixing of the random walks used to generate sample values of the \(\theta_i\). Within the adaptation duration, a scaled version of the covariance matrix of the sample values of the last \(N_{cov}\) samples (defined as the adaptation frequency in the UCSD_UQ engine) is used, to keep the acceptance rate in the range of 0.2 to 0.5.