2. Methods in SimCenterUQ Engine¶
2.1. Nataf transformation¶
Nataf transformation is introduced to standardize the interface between UQ methods and Simulation models. Nataf converts the samples in the physical space (X-space) into the standard normal samples (U-space), \(T:\rm{X} \rightarrow \rm{U}\), and vice versa, during UQ computations [Liu1986]. Specifically, the latter transformation, called inverse Nataf \(T^{-1}\), is performed each time the UQ engine generates sample points and calls external workflow applications so that the main UQ algorithms would face only the standard normal random variables. Among various standardization transformations, Nataf is one of the most popular methods which exploits marginal distributions of each physical variable and their correlation coefficients.
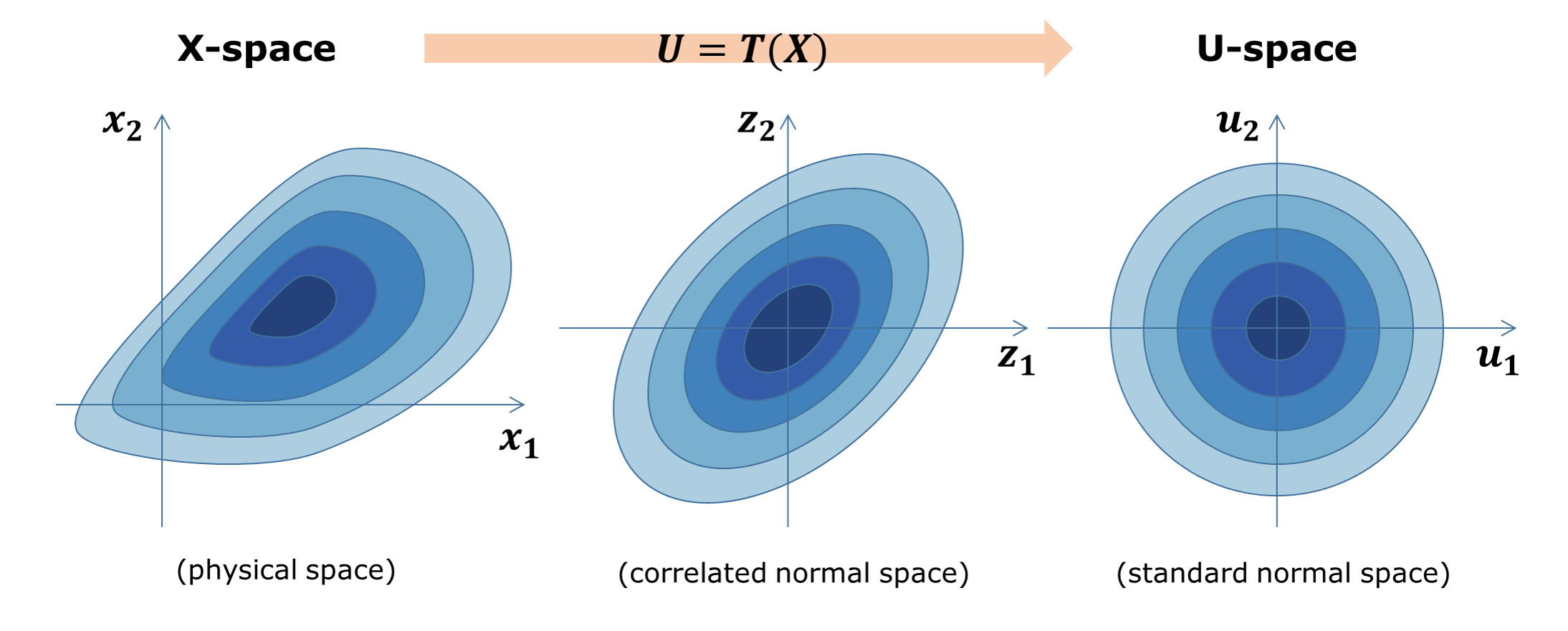
Fig. 2.1.1 Standardization of random variables using Nataf transformation¶
Note
(Ongoing implementation) All the custom UQ algorithms need to prepare for the standard Gaussian input while quoFEM intertwines with the simulation model to receive standard normal input u and gives physical \(y=G(u)\) back.
For the Nataf transformation, the SimCenterUQ engine borrows a part of the distribution class structure developed by the ERA group at the Technical University of Munich [ERA2019]
- Liu1986
Liu, P.L. and Der Kiureghian, A. (1986). Multivariate distribution models with prescribed marginals and covariances. Probabilistic Engineering Mechanics, 1(2), 105-112.
- ERA2019
Engineering Risk Analysis Group, Technische Universität München: https://www.bgu.tum.de/era/software/eradist/ (Matlab, python programs and documentations)
2.2. Global sensitivity analysis¶
Video Resources¶
Global Sensitivity Analysis: why, what, and how.
Click to replay the video from 2:14.
Variance-based global sensitivity indices¶
Global sensitivity analysis (GSA) is performed to quantify the contribution of each input variable to the uncertainty in QoI. Using the global sensitivity indices, users can set preferences between random variables considering both inherent randomness and its propagation through the model. GSA helps users to understand the overall impact of different sources of uncertainties, as well as accelerate UQ computations by focusing on dominant dimensions or screening out trivial input variables.
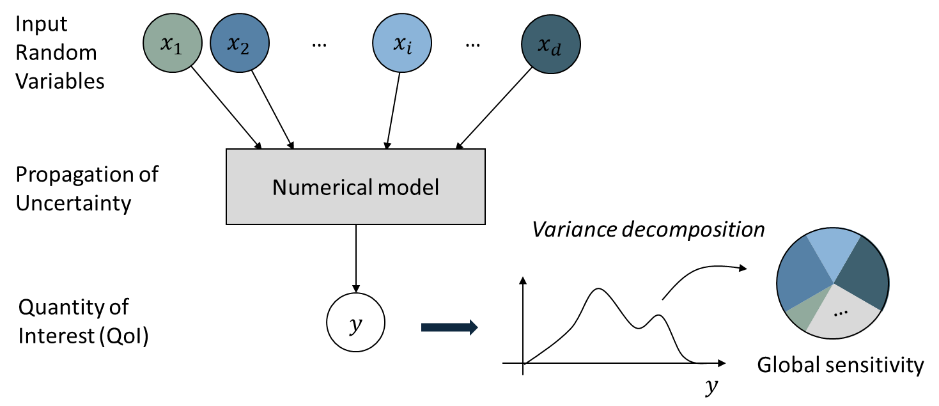
Fig. 2.2.19 Concept of Global Sensitivity Analysis¶
Sobol indices are widely used variance-based global sensitivity measures. It has two types: main effect and total effect sensitivity indices. The main effect index finds the fraction of variance in QoI that can be attributed to specific input random variable(s) but without considering the interactive effect with other input variables. The total effect index, on the other hand, additionally takes the interactions into account.
Given the output of model \(y=g(\boldsymbol{x})\) and input random variables \(\boldsymbol{x}=\{x_1,x_2, \cdots ,x_d\}\), the first-order main and total effect indices of each input variable is defined as
respectively, where \(\boldsymbol{x}_{\sim i}\) indicates the set of all input variables except \(x_i\). It is noteworthy that in both equations, the variance operator \(\text{Var}_{x_i}[\cdot]\) captures only the part of uncertainty associated with \(x_i\), while the mean operator \(\text{E}_{\boldsymbol{x}_{\sim i}}[\cdot]\) averages out all remaining uncertainties. From the definitions, two indices theoretically have values between zero and one. Eq. (2.2.1) can also be understood intuitively. For example, if the QoI is insensitive to \(x_i\), the term inside \(\text{Var}_{x_i}[\cdot]\) is nearly constant and \(S_i\) approaches zero. On the other hand, when one single variable \(x_i\) dominates QoI, inside \(\text{Var}_{x_i}[\cdot]\) is approximately the same as \(y\), and thus \(S_i\) approaches one. Eq. (2.2.2) can be understood in similar ways. The second-order main effect index that provides the pair-wise interaction effect is defined as
where \(\boldsymbol{x}_{\sim ij}\) indicates the set of all input variables except \(x_i\) and \(x_j\). The higher-order indices are derived likewise. Theoretically, When all the input variables are uncorrelated to each other, the following equality holds.
Note
The numerical results of global sensitivity analysis may show negative values due to the sampling variability
The numerical results of Eq. (2.2.4) for uncorrelated inputs may not hold due to the sampling variability and approximation errors. If this error is very high, the sensitivity index may not be reliable. However, the sensitivity rank between variables is relatively robust.
Estimation of Sobol indices using Probabilistic model-based global sensitivity analysis (PM-GSA)¶
GSA is typically computationally expensive. High computation cost attributes to the multiple integrations (\(d\)-dimensional) associated with the variance and expectation operations shown in Eqs. (2.2.1) and (2.2.2). To reduce the computational cost, efficient Monte Carlo methods, stochastic expansion methods, or meta-model-based methods can be employed. Among different approaches, the SimCenterUQ engine supports the probability model-based GSA (PM-GSA) framework developed by [Hu2019].
The framework first conducts ordinary MCS to obtain input-output data pairs. Then by extracting only a subset dimension of the dataset, the probability distribution of a reduced dimension can be approximated and used for estimating the Sobol index. Among different probability distribution models introduced in [Hu2019] the Gaussian mixture model is implemented in this engine to approximate this lower dimension distribution. For example, to identify 1st order main Sobol index for a variable \(x_i\), a bivariate Gaussian mixture model is fitted for the joint probability distribution of \(x_i\) and \(y\), i.e.
using the expectation-maximization (EM) algorithm. The mean operation Eq. (2.2.1) is then derived analytically from the Gaussian mixture model, while the variance is approximated to be the sample variance. Therefore, the accuracy of the method depends on the quality of the base samples as well as the fitness of the mixture model. The below figure summarizes the procedure of Gaussian mixture model-based PM-GSA introduced in [Hu2019]. The number of mixture components is optimized along with the mixture parameters during expectation-maximization iterations.
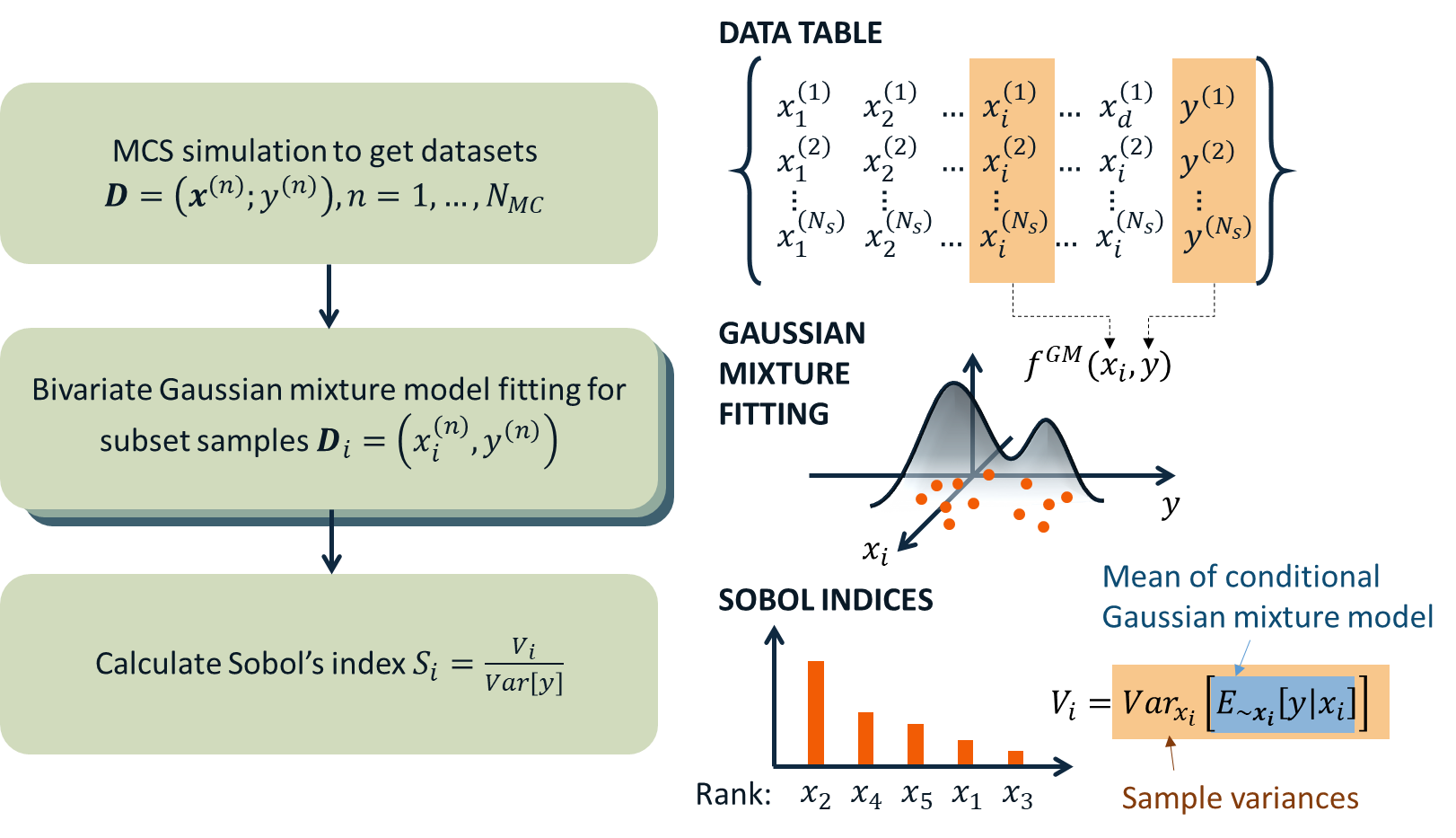
Fig. 2.2.20 Data-driven global sensitivity analysis by Hu and Mahadevan (2019)¶
Dealing with high-dimensional responses with PCA-PSA¶
When the number of the quantities of interest (QoI) is very large, it is computationally cumbersome to perform above Gaussian fitting independently for each QoI. To promote efficient global sensitivity analysis for such cases, SimCenterUQ provides the ‘principal component analysis-based PM-GSA’ module, which is referred to as PCA-PSA [Jung2022]. In this method, the dimension of QoI is first reduced by principal component analysis (PCA), and the conditional variance required to calculate the Sobol indices (the numerators in (2.2.1) and (2.2.2)) is approximately reconstructed from those of the conditional variance/covariance information of the reduced dimension variables. If the high-dimensional QoI has a linear data structure that be reconstructed with a small number of principal components, the computational gain of this approach can be significant. For example, suppose QoI can be reconstructed using 10 principal components. In that case, the Gaussian mixture fitting, which is the most time-consuming step of PM-GSA apart from FEM analysis, needs to be repeated only 10 times per random variable or group of random variables regardless of the actual dimension of QoI. This example shows how PCA-PSA can facilitate efficient global sensitivity analysis for a field (time series) QoI.
- Jung2022
Jung, W., & Taflanidis, A. A. (2023). Efficient global sensitivity analysis for high-dimensional outputs combining data-driven probability models and dimensionality reduction. Reliability Engineering & System Safety, 231, 108805.
Aggregated sensitivity index¶
When the quantities of interest (QoI) are given as a vector or field variable, an aggregated sensitivity index can provide insight into the system’s overall sensitivity characteristics. The aggregated sensitivity index achieves this by calculating the weighted average of the sensitivity indices of each QoI component, where the weights are proportional to the variances of the components [Jung2022]. Component sensitivity indices are useful for visualization, while the aggregated sensitivity index gives instant intuition on how much each variable influences the system response overall. See this example.
- Jung2022
Jung, W., & Taflanidis, A. A. (2023). Efficient global sensitivity analysis for high-dimensional outputs combining data-driven probability models and dimensionality reduction. Reliability Engineering & System Safety, 231, 108805.
2.3. Global surrogate modeling¶
Introduction to Gaussian process regression (Kriging)¶
Global surrogate modeling aims to build a regression model that reproduces the outcomes of computationally expensive high-fidelity simulations.
where the basic assumption is that the function evaluation speed of \(g^{\rm{sur}}(\boldsymbol{x})\) is incomparably faster than \(g^{\rm{ex}}(\boldsymbol{x})\). To perform surrogate modeling, we first need to acquire data samples, \((\boldsymbol{x},\boldsymbol{y})\), of exact model based on a few rounds of model evaluations, and then the function is interpolated and extrapolated based on the data set. Among various surrogate techniques, Kriging approximates the response surface using a Gaussian process model. Specifically, the Kriging surrogate model has the following form:
where the term \(\tilde{g}(\boldsymbol{x})^T\boldsymbol{\beta}\) captures the deterministic global trend via basis functions and linear combination coefficients \(\boldsymbol{\beta}\). The second term \(z(\boldsymbol{x})\) represents the residual and is modeled as a centered second-order stationary Gaussian process. The assumption is that the true residual value is one of the realizations of the random process:
Therefore, the main tasks of surrogate modeling are (1) to find optimal stochastic parameters \(\hat{\boldsymbol{\beta}}\) and \(\hat{K}(x_i,x_j)\) that best match the observations, and (2) to predict the response at an arbitrary sample point \(\boldsymbol{x^*}\) as a conditional distribution of \(f(\boldsymbol{y^*}|\boldsymbol{y^{obs}})\), exploiting the fact that \(\boldsymbol{y^*}\) and \(\boldsymbol{y^{obs}}\) are joint Gaussian distributions with known mean and covariances.
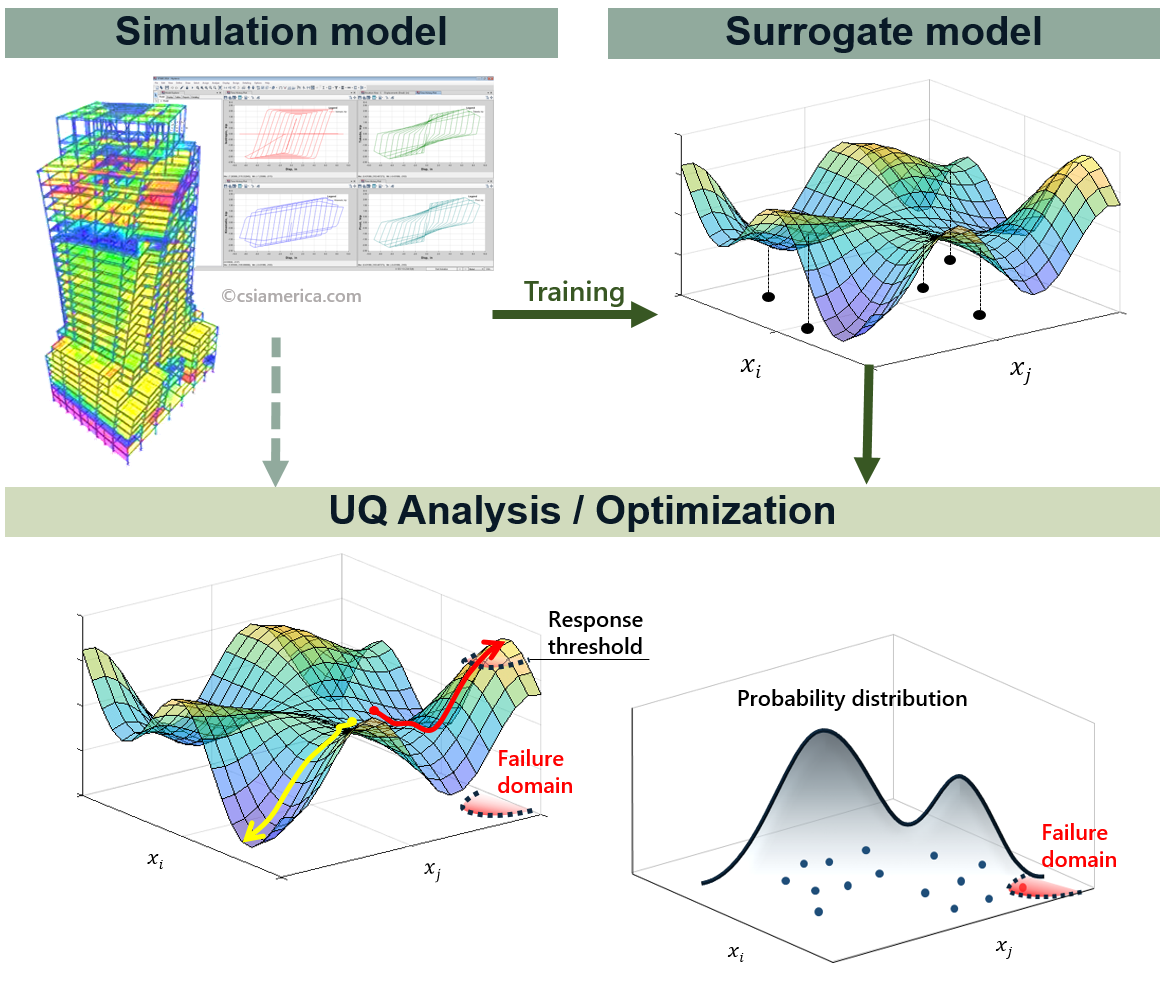
Fig. 2.3.1 Surrogate model for UQ/Optimization¶
Dealing with noisy measurements¶
In natural hazard applications, often the exact observations of \(\boldsymbol{y}\) are not available and only the noisy observations \(\boldsymbol{y^{obs}}\) are available:(2.3.4)¶\[ \boldsymbol{y^{obs}}=\boldsymbol{y} + \boldsymbol{\varepsilon} =g^{\rm{ex}} (\boldsymbol{x}) + \boldsymbol{\varepsilon}\]where a common assumption is that the measurement noise, \(\boldsymbol{\varepsilon}\), follows a white Gaussian distribution (i.e., \(\varepsilon\) is unbiased, follows a normal distribution with variance \(\tau\), and is independent of other observation noises). Additionally since the noise level is often unknown, \(\tau\) is also calibrated along with \(\beta\) and \(K(x_i,x_j)\). In such settings, the surrogate model estimation will not interpolate the observation outputs \(\boldsymbol{y^{obs}}\), but instead make a regression curve passing through the optimal estimation of the true underlying outputs \(\boldsymbol{y}\). In addition to the measurement noise, a mild amount of inherent uncertainty in the simulation model (mild compared to a global trend) can be accounted for in terms of the same noise parameter \(\varepsilon\).
Nugget effect: artificial noise for numerical stability
The constructed Kriging surrogate model is always smooth and continuous as it is a realization of a Gaussian process, while the actual response may be non-smooth, discontinuous, or highly variant that goes beyond the flexibility of the surrogate model. Especially when the measurements are noiseless, the Gaussian process training can suffer from numerical instability. In such ill-posed problems, the introduction of a small amount of artificial noise, often referred to as nugget, may significantly improve the algorithmic stability. In the quoFEM, the nugget parameter is automatically optimized in the loop along with the other parameters. (Note: technically, the nugget effect and measurement noise do not coincide in the mathematical formulation as the nugget effect conserves the interpolating property while measurement noise does not [Roustant2012]. However, this program treats the nugget as an artificial noise as its outcomes are often practically indistinguishable.)
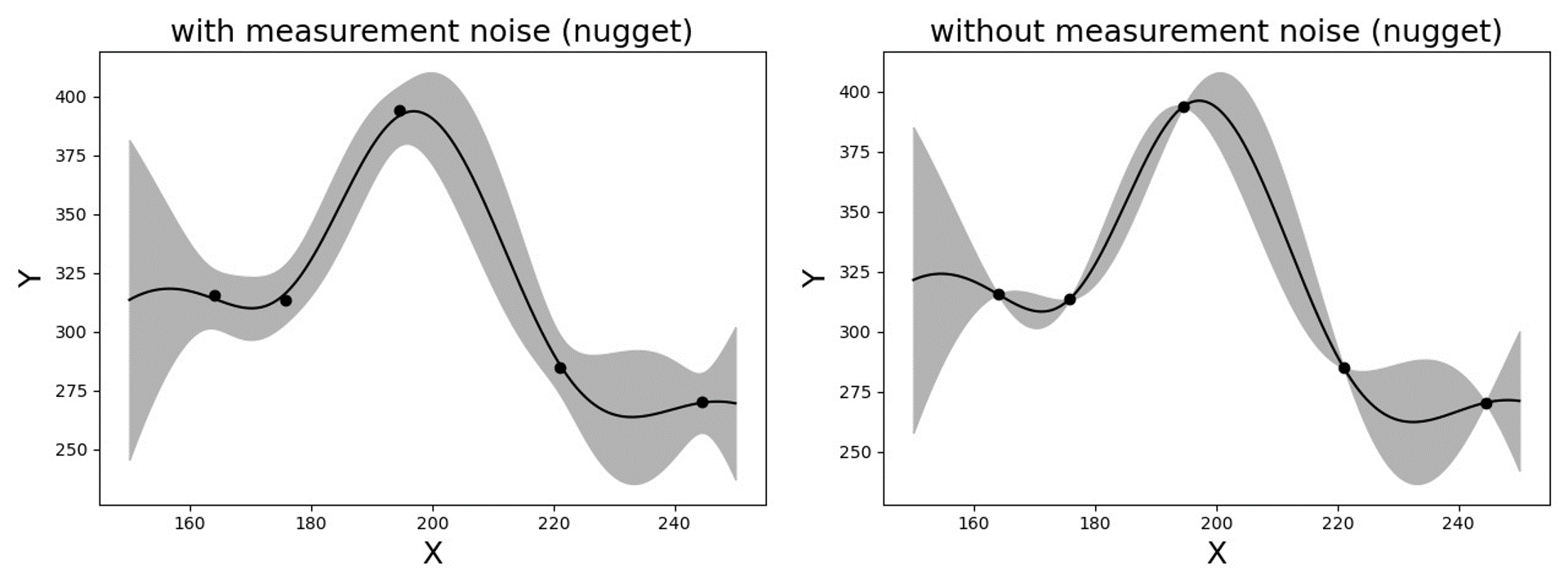
Fig. 2.3.2 Gaussian process regression with and without measurement noise ( or nugget effect)¶
Heteroscedastic measurement noise
When one expects a high noise level in the response observations with varying variance scales across the domain, one may want to consider modeling the heteroscedastic noise. Note that the observation noise here comes from the variability not captured by the RV values we defined (i.e., \(x\)). For example, mapping between structural parameters (\(x\)) and the earthquake response (\(y\)) typically requires heteroscedastic GP models to capture the effect of the aleatoric variability in the response ground motion time history. The below figure shows an example data shape for which a heteroscedastic GP model is required. quoFEM app introduces the stochastic Kriging algorithm in [Kyprioti2021] to achieve this, which relies on the so-called partial replication strategy, that is, to generate multiple realizations for a subset of inputs to examine response variance. In particular, a subset of initial samples are replicated to obtain variance estimates, i.e., variance realizations, at different sample locations, and these values are used to construct a variance-field model. Then by constraining the relative scales of the variance, the stochastic kriging emulator is trained using both replication and unique (non-replicated) samples. This example reproduces the results of Fig. 2.3.3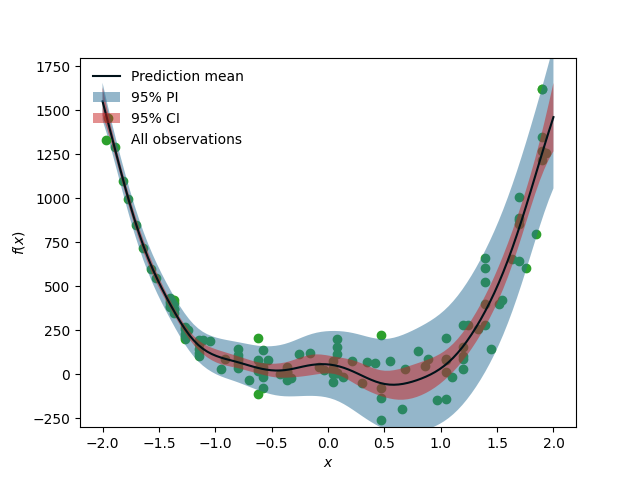
Fig. 2.3.3 When heteroscedastic GP is needed¶
Construction of the surrogate model¶
Input-Output settings¶
Input (RV) type |
Output (QoI) type |
||
|---|---|---|---|
Case1 |
Adaptive Design of Experiments (DoE) : a bounded variable space of \(\boldsymbol{x}\) |
Simulator : \(\boldsymbol{y}=g(\boldsymbol{x})\) |
|
Case2 |
Data set : {\(\boldsymbol{x_1,x_2, ... ,x_N}\)} |
Simulator : \(\boldsymbol{y}=g(\boldsymbol{x})\) |
|
Case3 |
Data set : {\(\boldsymbol{x_1,x_2, ... ,x_N}\)} |
Data set : {\(\boldsymbol{y_1,y_2, ... ,y_N}\)} |
|
Users have the following options:
Case1: users can provide a range of input variables (bounds) and a simulation model. After the initial space-filling phase using Latin hypercube sampling (LHS), adaptive design of experiment (DoE) is activated. Given current predictions, the next optimal simulation point is optimized such that the expected gain is maximized.
Case2: users can provide pairs of input-output dataset
Case3: users can provide input data points and a simulation model
Kernel and basis functions¶
The covariance kernel of the outcome process is unknown in most practical applications. Therefore, the mathematical form of the kernel is first assumed, and its parameters are calibrated based on the observation data. Following are some popular stationary covariance kernels.
Radial-basis function (RBF)
Radial-basis function, also known as squared-exponential or Gaussian kernel, is one of the most widely used covariance kernels.(2.3.5)¶\[k(\boldsymbol{x_i},\boldsymbol{x_j}) = \sigma\prod_{d=1}^{D} \exp\Bigg(-\frac{1}{2} \frac{(x_{i,d}-x_{j,d})^2}{l_d^2}\Bigg)\]where \(\boldsymbol{x_i}\) and \(\boldsymbol{x_j}\) are two arbitrary points in the domain and the hyperparameters, \(D\) is the number of input variables. The parameters \(\sigma\) and \(l_d\) respectively control the error scale and correlation length of the process.
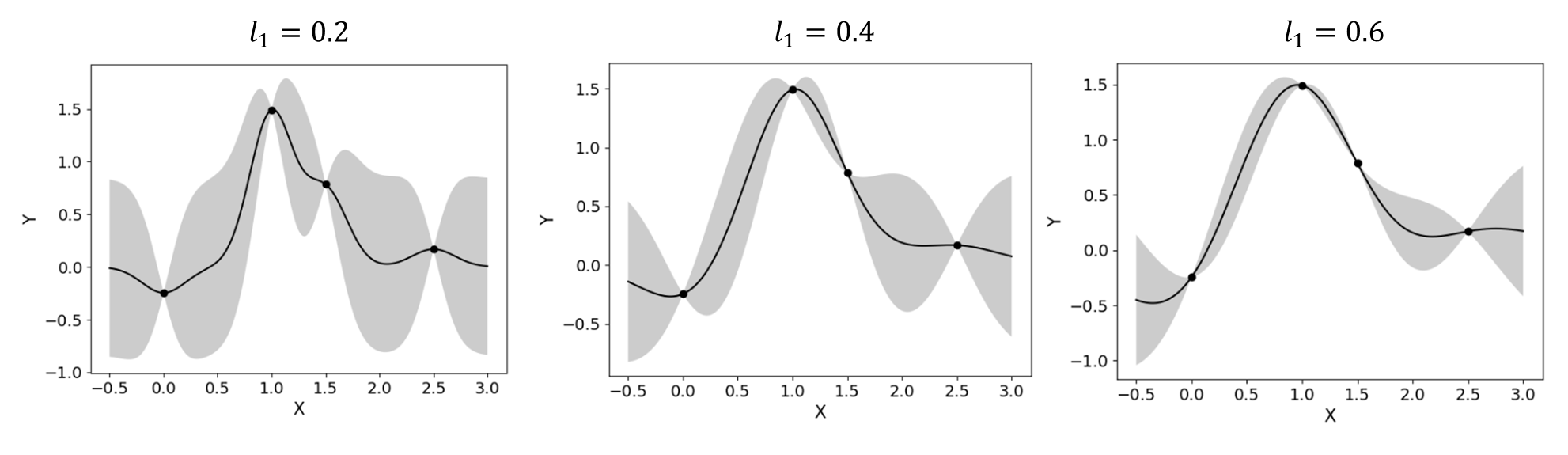
Fig. 2.3.4 Gaussian process regression for different correlation length parameters¶
Exponential
Similarly, the exponential covariance function is defined as follows.(2.3.6)¶\[k(\boldsymbol{x_i},\boldsymbol{x_j}) = \sigma\prod_{d=1}^{D} \exp\Bigg(-\frac{1}{2} \frac{|x_{i,d}-x_{j,d}|}{l_d}\Bigg)\]Matern Class
Matern class of covariance function is another popular choice. It has a positive shape parameter, often denoted as \(\nu\) which additionally determines the roughness of the parameters. For Kriging regression, \(\nu=5/2\) and \(\nu=3/2\) are known to be generally applicable choices considering the roughness property and the simplicity of the functional form. [Rasmussen2006](2.3.7)¶\[k(\boldsymbol{x_i},\boldsymbol{x_j}) = \sigma\prod_{d=1}^{D} g_d(h_{d})\]where \(h_d = x_{i,d}-x_{j,d}\) and(2.3.8)¶\[\begin{split}g_{d,\frac{5}{2}}(h_d) &= \Bigg(1+ \frac{\sqrt{5}|h_d|}{l_d}+\frac{5h_d^2}{3l_d^2}\Bigg)\exp\Bigg(-\frac{\sqrt{5}|h_d|}{l_d}\Bigg) \\ g_{d,\frac{3}{2}}(h_d) &= \Bigg(1+ \frac{\sqrt{3}|h_d|}{l_d}\Bigg)\exp\Bigg(-\frac{\sqrt{3}|h_d|}{l_d}\Bigg)\end{split}\]respectively for \(\nu=5/2\) (smoother) and \(\nu=3/2\) (rougher). It is noted in the literature that if \(\nu\) is greater than \(5/2\), the Matern kernel behaves similarly to the radial-basis function.
Once the kernel form is selected, the parameters are calibrated to maximize the likelihood of observations within the Gaussian process model. The default optimization function embedded in GPy is limited-memory BFGS with bound constraints (L-BFGS-B) algorithm from Python/Numpy package. [ShaffieldML2012]
Adaptive Design of Experiments (DoE)¶
In the case where bounds of input variables and a simulator model are provided (Case 1), model evaluation points can be selected by space-filling methods, e.g. Latin hypercube sampling (LHS). This is a non-adaptive Design of Experiments (DoE) in the sense that the whole samples can be located before running any simulations. On the other hand, the number of model evaluations can be reduced by selecting evaluation points adaptively after each run to get the best model improvements.
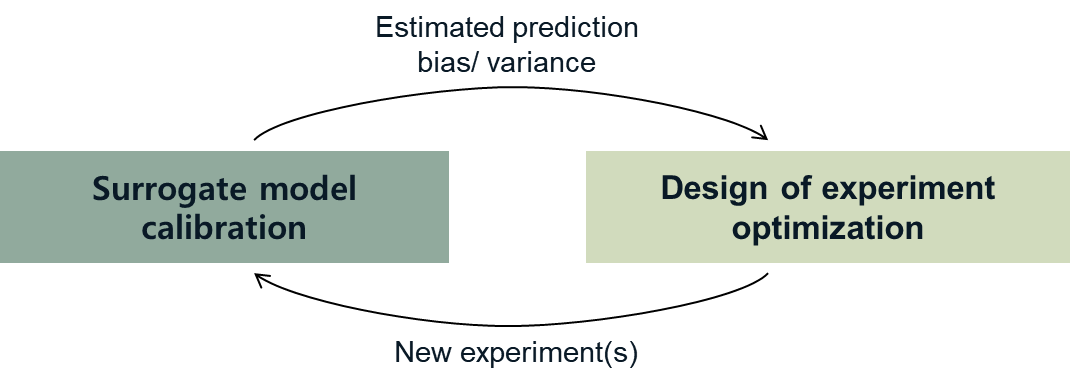
Fig. 2.3.5 Two optimizations in the design of experiments¶
However, as shown in the figure, adaptive DoE requires multiple optimization turns to find the optimal surrogate model parameters as well as the next optimal DoE. Therefore, it is noted that the adaptive DoE is efficient only when the model evaluation time is significantly greater than the optimization time.
Adaptive DoE algorithm: IMSEw, MMSEw ([Kyprioti2020])
The optimal design points can be selected by finding arguments that maximize (or minimize) the so-called score function. The score function in global surrogate modeling is often designed to predict the amount of reduced (or remaining) variance and bias after adding the new sample points. While there are many variations of the score function [Fuhg2020], in quoFEM, the modified integrated mean squared error (IMSE) from Kyprioti et al. (2020) is introduced as:
where \(\phi\) is bias measure from leave-one-out cross validation (LOOCV) analysis, \(\rho\) is a weighting coefficient, and \(\boldsymbol{\sigma_n}^2(\boldsymbol{x}|\boldsymbol{X,x_{new}})\) is the predictive variance after additional observation \(x_{new}\) [Kyprioti2020]. To find the sample location that gives minimum IMSE value, a two-step screening-clustering algorithm is implemented.
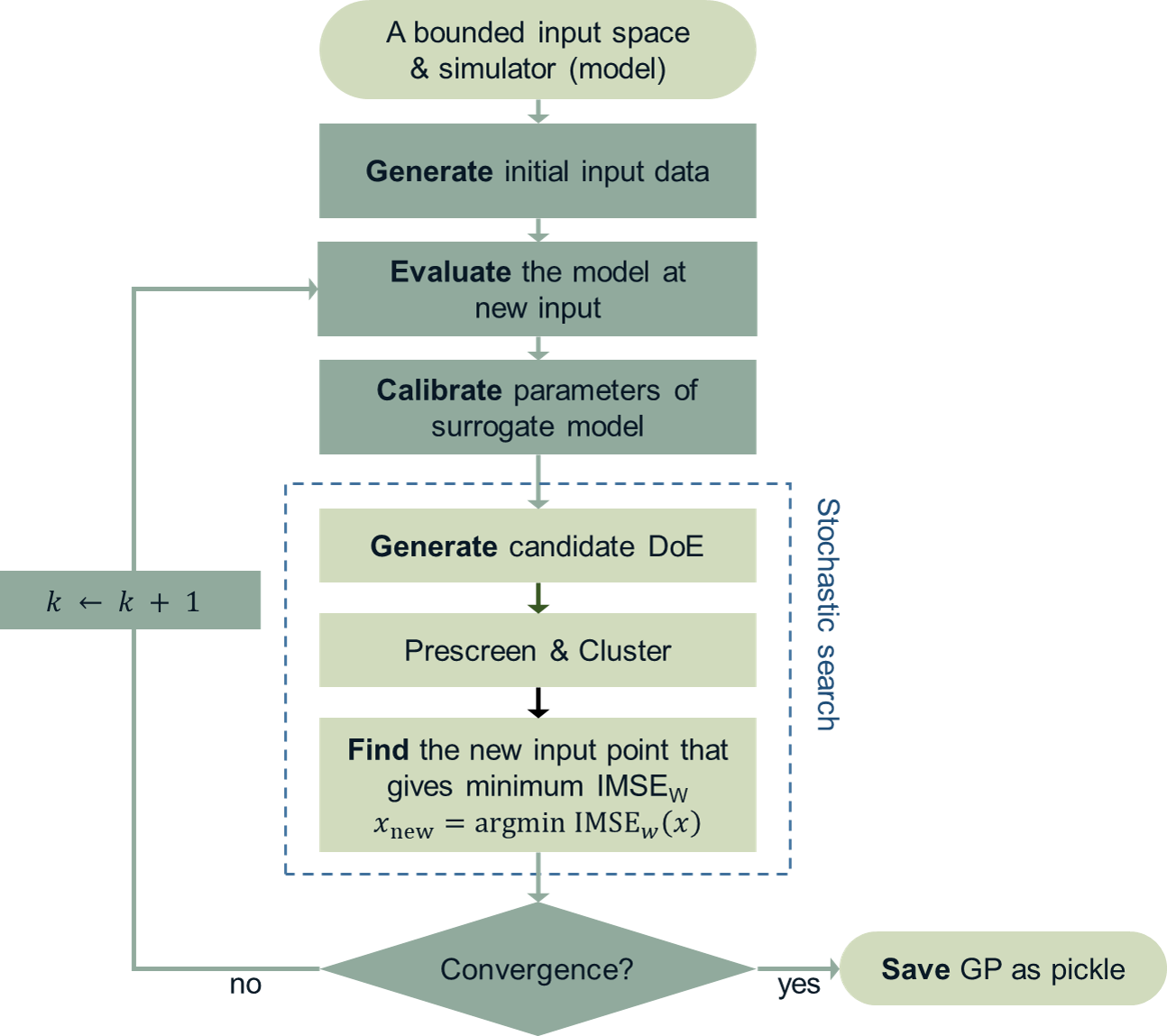
Fig. 2.3.6 Adaptive DoE procedure by Kyprioti et al. (2020) [Kyprioti2020]¶
Adaptive DoE algorithm: Pareto
Alternatively, multiple design points can be selected by a multi-objective optimization scheme. The variance measure and bias measure are defined by
Adaptive DoE is terminated when one of the three conditions is met:
Time: analysis time exceeds a predefined (rough) time constraint
Count: the number of model evaluations exceeds a predefined count constraint
Accuracy: the accuracy measure of the model meets a predefined convergence level
Verification of surrogate model¶
Once the training is completed, the following three verification measures are presented based on leave-one-out cross-validation (LOOCV) error estimation.
Leave-one-out cross-validation (LOOCV)
LOOCV prediction \(\hat{\boldsymbol{y}}_k\) at each sample location \(\boldsymbol{x}_k\) is obtained by the following procedure: A temporary surrogate model \(\hat{\boldsymbol{y}}=g^{sur}_{loo,k}(\boldsymbol{\boldsymbol{x}})\) is constructed using the samples \(\{\boldsymbol{x}_1,\boldsymbol{x}_2,...,\boldsymbol{x}_{k-1},\boldsymbol{x}_{k+1},...,\boldsymbol{x}_N\}\) and the calibrated parameters, and the prediction \(\hat{\boldsymbol{y}}_k=g^{sur}_{loo,k}(\boldsymbol{x}_k)\) is compared with the exact outcome.
We provide different verification measures for two different cases.
When nugget variance is low: The LOOCV prediction \(\hat{\boldsymbol{y}}_k\) is expected to match the exact outcome \(\boldsymbol{y_k}=g(\boldsymbol{x}_k)\) when the surrogate model is well-trained. To quantify the goodness, R2 error, normalized root-mean-squared-error (NRMSE), and correlation coefficient are provided:
R2 error
R2 error is defined in terms of the total sum of squares over the residual sum of squares(2.3.11)¶\[\begin{align*} R^2 &= 1 - \frac{\sum^N_{k=1} (\hat{y}_k-\mu_\hat{y})^2}{\sum^N_{k=1} (\hat{y}_k-y_k)^2} \end{align*}\]The surrogate model is considered well-trained when the R2 (<1) approaches 1Normalized root-mean-squared-error (NRMSE)
(2.3.12)¶\[\begin{align*} \rm{NRMSE} ~ &= \frac{\sqrt{\frac{1}{N_t} \sum^{N_t}_{k=1} (y_k-\hat{y}_k)^2}}{\max_{k=1,...,N_t}(y_k)-\min_{k=1,...,N_t}(y_k)} \end{align*}\]The surrogate model is considered well-trained when the NRMSE (>0) approaches 0Correlation coefficient
Correlation coefficient is a statistic that measures a linear correlation between two variables(2.3.13)¶\[ \rho_{y,\hat{y}} = \frac{\sum^N_{k=1}(y_k-\mu_{y})(\hat{y}_k-\mu_{\hat{y}})} {\sigma_y \sigma_\hat{y}}\]where\(\mu_{y}\) : mean of \(\{y_k\}\)\(\mu_{\hat{y}}\): mean of \(\{\hat{y}_k\}\)\(\sigma_{y}\): standard deviation of \(\{y_k\}\)\(\sigma_{\hat{y}}\): standard deviation of \(\{\hat{y}_k\}\)The surrogate model is considered well-trained when the correlation coefficient ( \(-1<\rho<1\) ) approaches 1
Note
Since these measures are calculated from the cross-validation predictions rather than external validation predictions, they can be biased, particularly when a highly localized nonlinear range exists in the actual response surface and those regions are not covered by the training samples.
When nugget variance is high: The distance between LOOCV prediction \(\hat{\boldsymbol{y}}_k\) and the exact outcome \(\boldsymbol{y_k}=g(\boldsymbol{x}_k)\) is expected to follow a normal distribution when the surrogate model is well-trained. To quantify the goodness, inter-quartile ratio (IQR) and Cramer-Von Mises statistics can be evaluated:
Inter-quartile ratio (IQR): IQR provides the ratio of the sample QoIs that lies in 25-75% LOOCV prediction bounds (interquartile range). The IQR values should theoretically approach 0.5 if the prediction is accurate.
Cramer-Von Mises statistics: Cramer-Von Mises statistics calculates the normality score. GP assumes that the observations follow a normal distribution conditional on the input parameters. To assess the normality of the model predictions, the difference between the mean prediction \(\hat{y}_k\) and the sample observation \(y_k\) value is divided by the standard deviation prediction from surrogate \(\hat{\sigma}_{y,k}\):
(2.3.14)¶\[ u_k = \frac{y_k-\hat{y}_k} {\hat{\sigma}_{y,k}}\]If the values of \({u_k}\) follow the standard normal distribution, the resulting surrogate model may be considered well-constructed. The Cramer-Von Mises test is calculated using the
scipy.stats.cramervonmisesfunction in the Python package Scipy, and the resulting p-value is displayed. Conventionally, if the p-value exceeds a significance threshold, e.g. 0.05, the null hypothesis that the samples are from a normal distribution is not rejected, meaning the samples may be considered to follow a Gaussian distribution.
- Rasmussen2006
Rasmussen, C.E. and Williams, C.K. (2006). Gaussian Process for Machine Learning. Cambridge, MA: The MIT Press, 2006 (available online at http://www.gaussianprocess.org/gpml/)
- Kyprioti2020(1,2,3)
Kyprioti, A.P., Zhang, J., and Taflanidis, A.A. (2020). Adaptive design of experiments for global Kriging metamodeling through cross-validation information. Structural and Multidisciplinary Optimization, 1-23.
- Kyprioti2021
Kyprioti, A.P. and Taflanidis, A.A., (2021). Kriging metamodeling for seismic response distribution estimation. Earthquake Engineering & Structural Dynamics, 50(13), pp.3550-3576.
- ShaffieldML2012
GPy, A Gaussian process framework in Python, http://github.com/SheffieldML/GPy, since 2012
- Sacks1989
Sacks J.,Welch W.J.,Mitchell T.J.,Wynn H.P. (1989). Design and analysis of computer experiments. Stat Sci 4(4):409–435
- Fuhg2020
Fuhg, J.N., Fau, A., and Nackenhorst, U. (2020). State-of-the-art and comparative review of adaptive sampling methods for kriging. Archives of Computational Methods in Engineering, 1-59.
- Roustant2012
Roustant, O., Ginsbourger, D., and Deville, Y. (2012). DiceKriging, DiceOptim: Two R packages for the analysis of computer experiments by kriging-based metamodeling and optimization. Journal of Statistical Software, 21:1–55
2.4. Multi-fidelity Monte Carlo (MFMC)¶
Models with different infidelities¶
When one has multiple models of a target system with different fidelities, one can introduce multi-fidelity Monte Carlo (MFMC) methods. MFMC helps us to reduce the high-fidelity simulation runs by leveraging a large number of low-fidelity simulations. The high-fidelity and low-fidelity models are defined as the following.
High-fidelity (HF) model: The model with the desired level of accuracy and high computational cost.
Low-fidelity (LF) model(s): The model(s) with lower computational cost and lower accuracy.
The goal of MFMC is to estimate the statistics of the HF model using a small number of HF simulations and a large number of LF simulations. Those fidelities can be attributed to the different idealization of models as shown in Fig. 2.4.1 (e.g. reduced order model), or models with the same idealization in different resolutions (e.g. coarser mesh or grids). The latter is also referred to as multi-level Monte Carlo (MLMC).
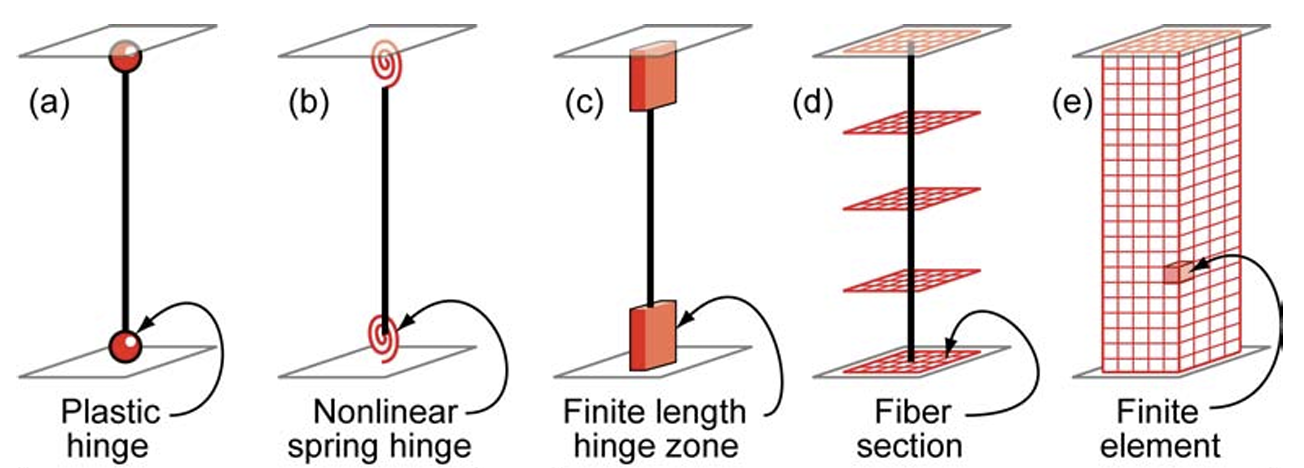
Fig. 2.4.1 Idealized models of beam-column elements (Fig 2.1 in [Deierlein2010])¶
- Deierlein2010
Deierlein, Gregory G., Andrei M. Reinhorn, and Michael R. Willford. (2010). Nonlinear structural analysis for seismic design. NEHRP seismic design technical brief 4 : 1-36.
Note
The concept of MFMC is different from that of multi-model forward propagation referred to in other parts of the documentation.
MFMC algorithm has a clear hierarchy between different models in terms of accuracy. A good MFMC algorithm will give accurate estimates of the statistics of the HF model.
Multi-model forward propagation is used when one has different alternative models without a clear hierarchy in accuracy, meaning for each model, we have a certain belief that this model gives true value. Therefore, a good multi-model forward propagation algorithm will give the final estimate that compromises the estimation from different models by considering how much belief we have in each model.
Pre-execution checklist for MFMC¶
Before running the MFMC simulation model, the users are advised to check the validity and effectiveness of MFMC for their problem. Only when the below conditions are satisfied, the users are expected to gain meaningful benefits by using MFMC compared to only HF simulations:
The models should take the same input random variables and produce the same output quantities of interest. For example, if the target system is a structure, if one model takes stiffness as a random variable and the other does not, the model violates the problem definition. Similarly, if \(j\)-th output of the HF model is the 1st-floor inter-story drift, \(j\)-th output of the LF model should also be the 1st-floor inter-story drift.
The models should have a clear hierarchy in terms of accuracy and time. When the HF and LF model responses are different, the assumption is that the HF response is always accurate. Therefore, if an HF model runs faster than the LF model, it is optimal to always run only the HF model, and there is no reason to introduce MFMC.
The response of different models should have a high correlation. The efficiency of MFMC heavily depends on the correlation between the HF and LF model outputs. Only if the correlation is fairly high, the MF estimation is meaningfully efficient than conducting only HF simulations.
The efficiency of MFMC can be evaluated using the speed-up ratio, defined as the reduction of computational effort you need to get the same Monte Carlo statistical accuracy by the MFMC and direct Monte Carlo method. Fig. 2.4.2 shows the expected speed-up factor for different computation time ratios and correlation coefficient values. One can notice that only when the ratio of the model evaluation time is greater than 100 and when the correlation is greater than 0.85-0.9, the expected speed-up is significant [Patsialis2021]. The formulation used to estimate the speed-up ratio can be found at the end of this section.
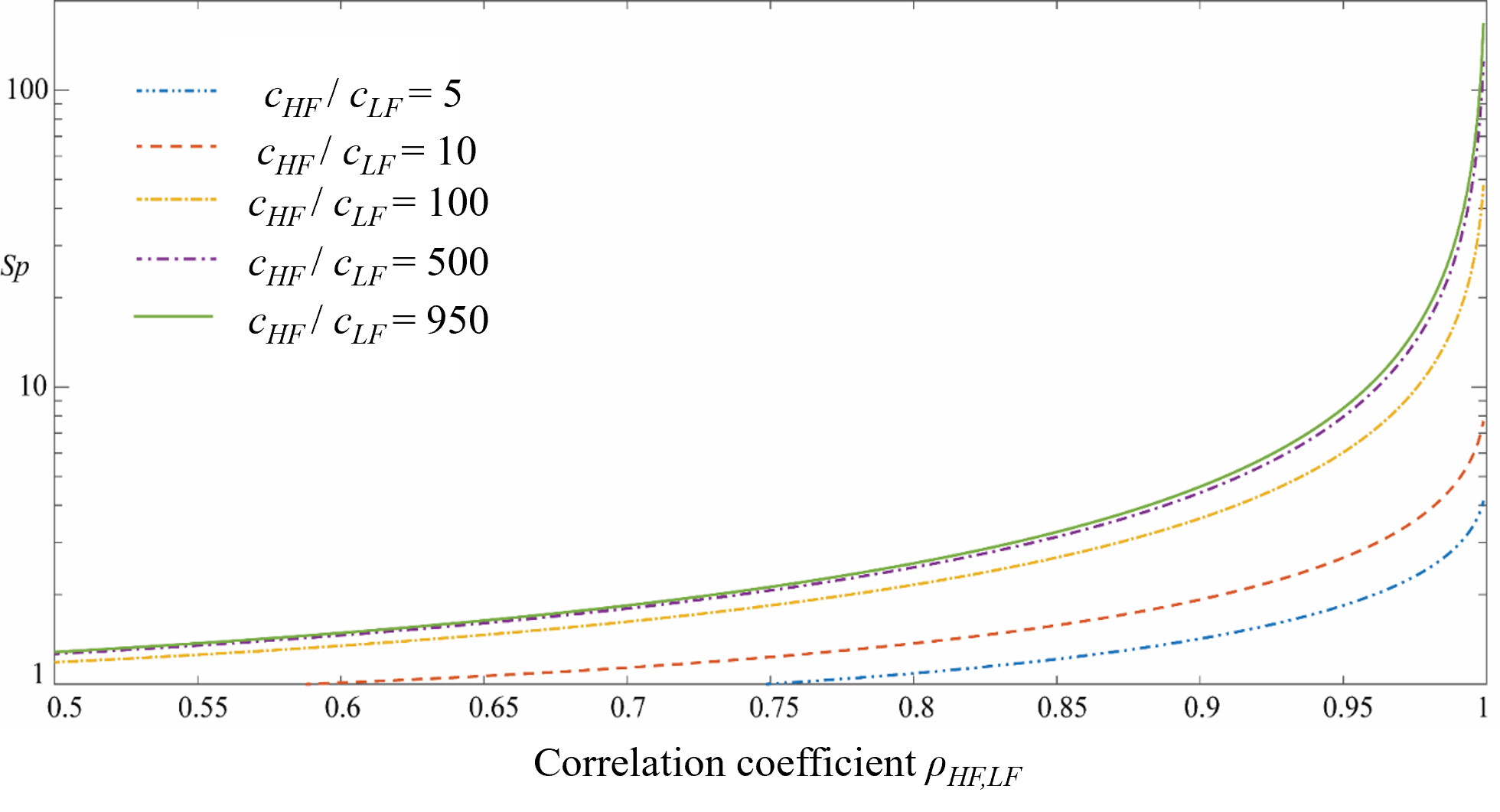
Fig. 2.4.2 Speed-up offered by the MFMC estimation (\(c_{HF}\): HF model evaluation time, \(c_{LF}\): LF model evaluation time, \(\rho_{LF,HF}\): correlation between HF and LF responses)¶
Algorithm details¶
The implementation of MFMC in quoFEM follows that of [Patsialis2021] which is based on the original work of [Peherstorfer2016]. Let us denote the HF and LF output for a given input \(x\) as
The goal of MFMC is to estimate the mean and variance of \(y_{HF}\), given some distribution of \(\boldsymbol{x}\) and computational budget, with the highest accuracy. The MFMC consists of three steps.
Note
For notational simplicity, the procedure presented on this page is the simplest case where we have a single LF model and a single output, aiming to estimate first-order statistics. However, once one understands the simplest case, the extension into the advanced cases is fairly straightforward.
For multiple LF models, a similar formulation can be found in the literature. ([Patsialis2021], [Peherstorfer2016], etc).
For multiple outputs \(y_{HF}\) and \(y_{LF}\) in the formulations can respectively be replaced with \(y_{j,HF}\) and \(y_{j,LF}\), meaning it is \(j\)-th output of the models.
The presented procedure leads to the estimation of the mean of \(\rm{E}[y_{HF}]\). The variance can be estimated by replacing \(y_{HF}\) and \(y_{LF}\) with \(y^2_{HF}\) and \(y^2_{LF}\), respectively, which lead to the estimation of \(\rm{E}[y_{HF}^2]\) and additionally introducing a post-processing step to subtract \(\rm{E}[y_{HF}]^2\). Other higher-order statistics can be estimated similarly.
The current implementation can accommodate multiple LF models, process multiple outputs, and output MFMC estimates of the variance. The complete formulations can be found in the literature ([Patsialis2021], [Peherstorfer2016], etc).
Step 1: Pilot Simulations

Fig. 2.4.3 Step 1: Pilot Simulation¶
Randomly generate \(N_p\) sample points and run both HF and LF simulations. Compute the correlation between two model outputs (\(\rho_{LF,HF}\)) and estimate the average model evaluation times (\(c_{HF}\) and \(c_{LF}\)). The optimal ratio of HF and LF simulation runs can be decided by
(2.4.3)¶\[r^* = \sqrt{ \frac{c_{HF}\rho^2_{LF,HF}}{c_{LF}(1-\rho^2_{LF,HF})} }\]
Considering the remaining computational budget (\(C_T\)), the optimal number of HF and LF simulations (denoted as \(N_1\) and \(N_1+N_2\)) can ideally be decided such that \(N_1:(N_1+N_2) = 1:r\) and \(C_T = N_1 c_{HF} + (N_1+N_2) c_{LF}\). However, the due to practical obstacles (e.g. when multiple outputs are simultaneously considered or when the number of pilot samples exceeds \(N_1\)) the final ratio \(r\) can be different from the optimal one.
Note
When multiple outputs are considered, the simulation ratio is chosen to be the average of the optimal ratios (\(r^*\)) for different outputs.
Step 2: Final Simulations
Randomly generate \(N_1-N_p\) sample points and run both HF and LF. We now have \(N_1\) data points \(\{\boldsymbol{x}^{(n)}\}_{n=1,...,N_1}\) , and corresponding outputs \(\{y^{(n)}_{HF}\}_{n=1,...,N_1}\) and \(\{y^{(n)}_{LF}\}_{n=1,...,N_1}\). Let us denote a set of these data points as \(D_1\).
Generate \(N_2\) more sample points and run only LF simulations. We now have \(N_2\) more data points \(\{\boldsymbol{x}^{(n)}\}_{n=N_1,...,N_1+N_2}\), and corresponding LF outputs \(\{y^{(n)}_{LF}\}_{n=N_1,...,N_1+N_2}\). Let us denote this batch of data points as \(D_2\).
Step 3: Estimation of Statistics

Fig. 2.4.4 Step 3: Estimation of Statistics¶
Using data sets \(D_1\) and \(D_2\), the final statistics are estimated as
(2.4.4)¶\[\mu_{MF} = \mu_{HF}+\rho_{LF,HF}\frac{\sigma_{HF}}{\sigma_{LF2}}\left( \mu_{LF2}-\mu_{LF1} \right)\]
where
(2.4.5)¶\[\mu_{HF} = \frac{1}{N_1} \sum^{N_1}_{n=1} y^{(n)}_{HF}\](2.4.6)¶\[\sigma_{HF}^2 = \frac{1}{N_1} \sum^{N_1}_{n=1} (y^{(n)}_{HF} - \mu_{HF})^2\](2.4.7)¶\[\mu_{LF1} = \frac{1}{N_1} \sum^{N_1}_{n=1} y^{(n)}_{LF}\](2.4.8)¶\[\rho_{LF,HF} = \frac{\sum^{N_1}_{n=1}(y^{(n)}_{LF} - \mu_{LF1})(y^{(n)}_{HF} - \mu_{HF})}{\sqrt{ \sum^{N_1}_{n=1}(y^{(n)}_{LF} - \mu_{LF1})^2 \sum^{N_1}_{n=1}(y^{(n)}_{HF} - \mu_{HF})^2 }}\](2.4.9)¶\[\mu_{LF2} = \frac{1}{N_1+N_2} \sum^{N_1+N_2}_{n=1} y^{(n)}_{LF}\](2.4.10)¶\[\sigma_{LF2}^2 = \frac{1}{N_1+N_2} \sum^{N_1+N_2}_{n=1} (y^{(n)}_{LF} - \mu_{LF2})^2\]
Note that the first four terms are evaluated using only \(D_1\), and the last two terms are evaluated using both \(D_1\) and \(D_2\). Additionally, the precision of the estimation can be measured by the coefficient of variation (c.o.v):
(2.4.11)¶\[c.o.v[\mu_{MF}] = \frac{\sigma_{HF}}{N_1} \left(1-\left(1-\frac{1}{r}\right)\rho_{LF,HF}^2 \right)\]
Speed-up¶
The speed-up is an efficiency metric that represents the computational time you save by using MFMC compared to only HF simulations to reach the same level of accuracy (same variance).
(2.4.12)¶\[SP_i = \frac{c_{HF}}{c_{HF}+rc_{LF}} \left(1-\left(1-\frac{1}{r}\right)\rho_{LF,HF}^2 \right)^{-1}\]
- Patsialis2021(1,2,3,4)
Patsialis, D., and A. A. Taflanidis. (2021). Multi-fidelity Monte Carlo for seismic risk assessment applications. Structural Safety 93 (2021): 102129.
- Peherstorfer2016(1,2,3)
Peherstorfer, B., Willcox, K., Gunzburger, M. (2016). Optimal model management for multifidelity Monte Carlo estimation. SIAM Journal on Scientific Computing 38:A3163-A94.