3.1.2.5. Bayesian Calibration¶
The methods in the Bayesian calibration category are concerned with the estimation of the probability distribution of the parameter values given observational measurements. Unlike deterministic parameter estimation methods, in which the user provides a range and an initial starting point for the input random variables when using the methods in this category, the user has some idea about the probability distribution of the parameter values. This information is provided in the form of the prior distributions in the RV panel. The Bayesian calibration methods take this prior information and combine it with information from the observed data provided in the UQ panel to infer posterior distributions of the parameter values. A Bayesian updating paradigm is followed, where the prior distribution on a parameter is updated through a Bayesian framework involving experimental data and a likelihood function. The likelihood function specifies the likelihood that a particular parameter value of the model produced the observed data. Dakota uses a Gaussian likelihood function. The algorithms that generate the samples to characterize the posterior distributions are typically based on some Markov Chain Monte Carlo (MCMC) methods. Currently, quoFEM app provides access to the DREAM algorithm implemented in Dakota.
DREAM¶
The Differential Evolution Adaptive Metropolis ([DREAM]) method runs multiple Markov chains simultaneously for global exploration of the parameter space and automatically tunes and scales the orientation of the proposal distributions in randomized subspaces during the search. Fig. 3.1.2.5.1 shows the input panel corresponding to the DREAM method. The required inputs for this method are:
# Chains: number of chains in the DREAM algorithm
# Chain Samples: number of sample values to be drawn from the posterior probability distribution of the parameters
# Burn-in Samples: the number of samples at the beginning of the chain that are discarded
Jump Step: a long step is forced every Jump Step number of samples in the DREAM algorithm
Seed: seed of the random number generator, this option is provided for repeatability. If the same analysis is run multiple times with the same seed, the results will be identical from all the runs. If the same analysis is run with differing seed values, the results from all the runs will not be identical.
Calibration data file: the path to the file that contains the calibration data (i.e., the measured values of the responses).
Note
Calibration data file requirements
The data are provided in the calibration data file, which must fulfill the following requirements:
Each row of the calibration data file contains data from one experiment. The individual entries in every row of this file can be separated by spaces, tabs, or commas.
The number of entries in each row must equal the sum of the length of all outputs defined in the QoI panel.
The order of the entries in each row of the calibration data file must match the order in which the outputs are defined in the QoI panel and must correspond to the output from the computational model in the
results.outfile.
For example, if there are data from two experiments, and there are 2 response quantities, of length 2 and 1 respectively, then there must be two rows of values in the calibration data file. The length of each row must be 3, where the first two values in each row correspond to the first response quantity and the third value in each row corresponds to the second response quantity.
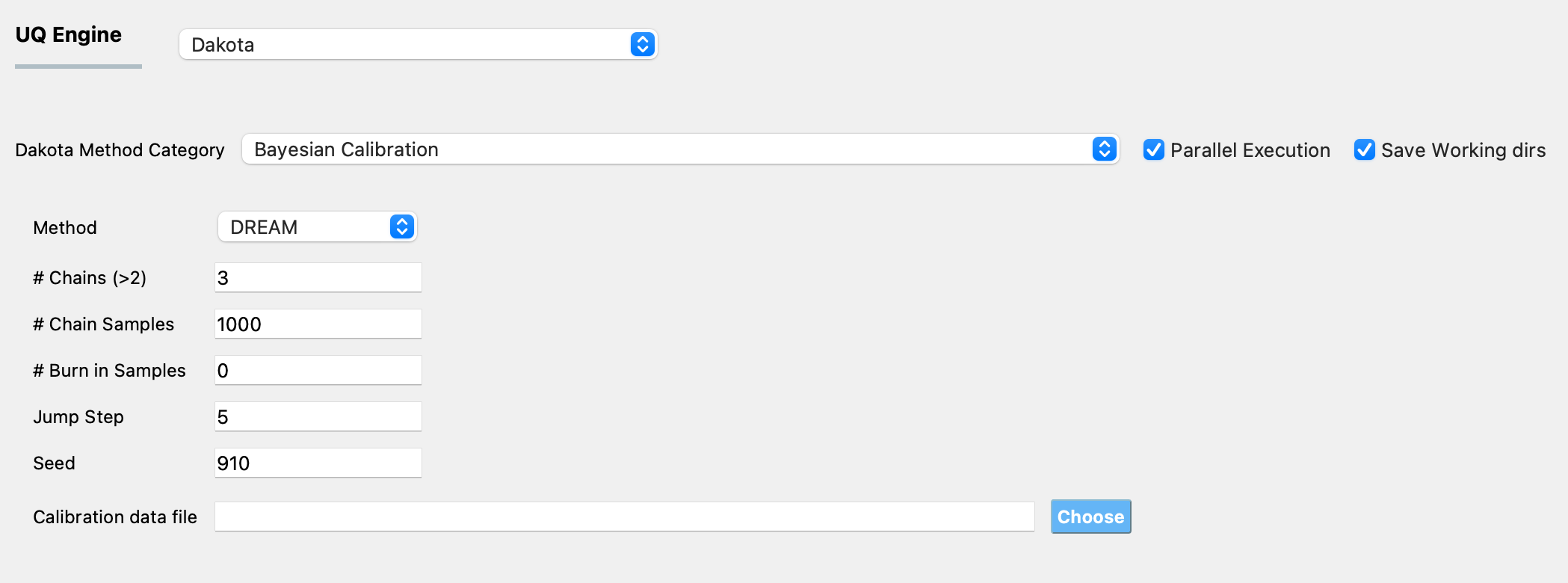
Fig. 3.1.2.5.1 DREAM input panel.¶
- DREAM
Vrugt, C. J. F. ter Braak, C. G. H. Diks, B. A. Robinson, J. M. Hyman, and D. Higdon. Accelerating Markov chain Monte Carlo simulation by self-adaptive differential evolution with randomized subspace sampling. International Journal of Nonlinear Scientific Numerical Simulation, 10(3), 2009. 1804, 2550