3.1.2.1. Forward Propagation¶
The forward propagation analysis provides a probabilistic understanding of output variables by producing sample realizations and statistical moments (mean, standard deviation, skewness, and kurtosis) of the quantities of interest. Currently, four sampling methods are available:
Monte Carlo Sampling (MCS)
Latin Hypercube Sampling (LHS)
and sampling based on surrogate models, including:
Gaussian Process Regression (GPR)
Polynomial Chaos Expansion (PCE)
Depending on the option selected, the user must specify the appropriate input parameters. For instance, for MCS, the number of samples specifies the number of simulations to be performed, and providing a seed value for the pseudo-random number generator will produce the same sequence of random numbers allowing the user to reproduce the sampling results multiple times. The user selects the sampling method from the dropdown Dakota Method Category menu. Additional information regarding sampling techniques offered in Dakota can be found here.
Monte Carlo Sampling (MCS)¶
MCS is among the most robust and universally applicable sampling methods. Moreover, the convergence rate of MCS methods is independent of the problem dimensionality, albeit the convergence rate of such MCS methods is relatively slow at \(N^{-1/2}\). In MCS, a sample drawn at any step is independent of all previous samples.
Fig. 3.1.2.1.1 shows the input panel corresponding to the Monte Carlo Sampling setting. Two input parameters need to be specified: (1) the number of samples of the output to be produced, which is equal to the number of times the model is evaluated, and (2) the seed for the pseudo-random number generator.
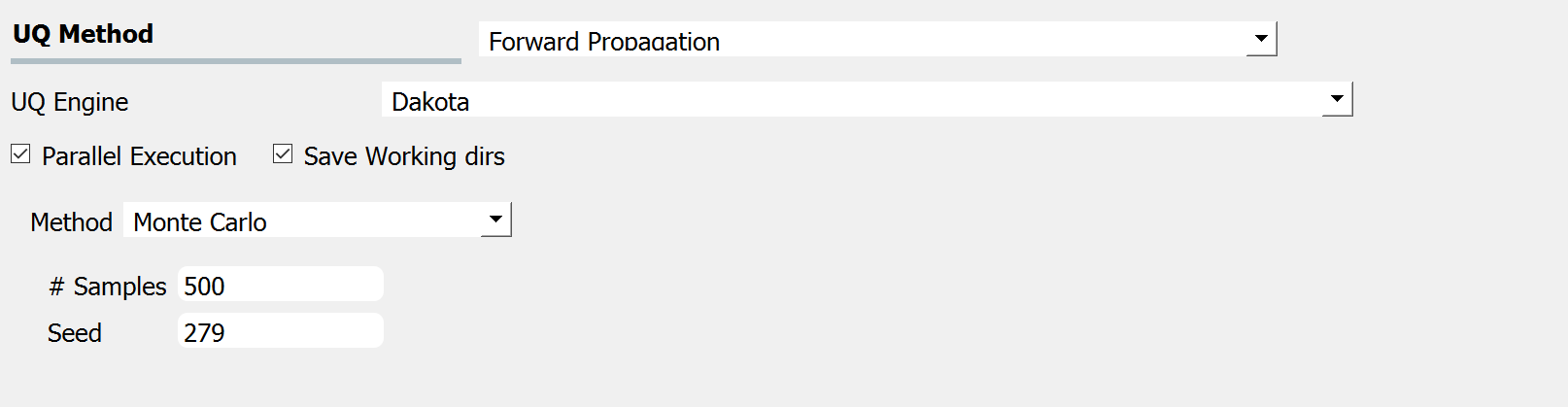
Fig. 3.1.2.1.1 Monte Carlo Sampling input panel.¶
Latin Hypercube Sampling (LHS)¶
The conventional Monte Carlo method generates each sample independently, which may produce undesired clusters and gaps between the samples arising from the sampling variability. On the other hand, Latin hypercube sampling (LHS) aims to prevent those gaps and clusters by ‘evenly’ spreading out the samples throughout the whole input domain. This can significantly reduce the sampling variability and facilitate faster convergence of the probabilistic statistics. In particular, LHS divides the input domain of each variable into N intervals with equal probability and locates the samples such that only one sample lies on each interval. This strategy forces the samples to be more uniformly spread across the domain. In general, LHS is encouraged over MCS as it provides unbiased estimation with a smaller standard error. For example, this article suggests that the convergence rate of a sample mean is about quadratically faster with LHS than with Monte Carlo simulation. However, it is noted that one drawback of LHS is that there is no closed-form expression to quantify the error level of the estimators. This means that the user may need to perform multiple batch samplings to quantify the error from the sample variability
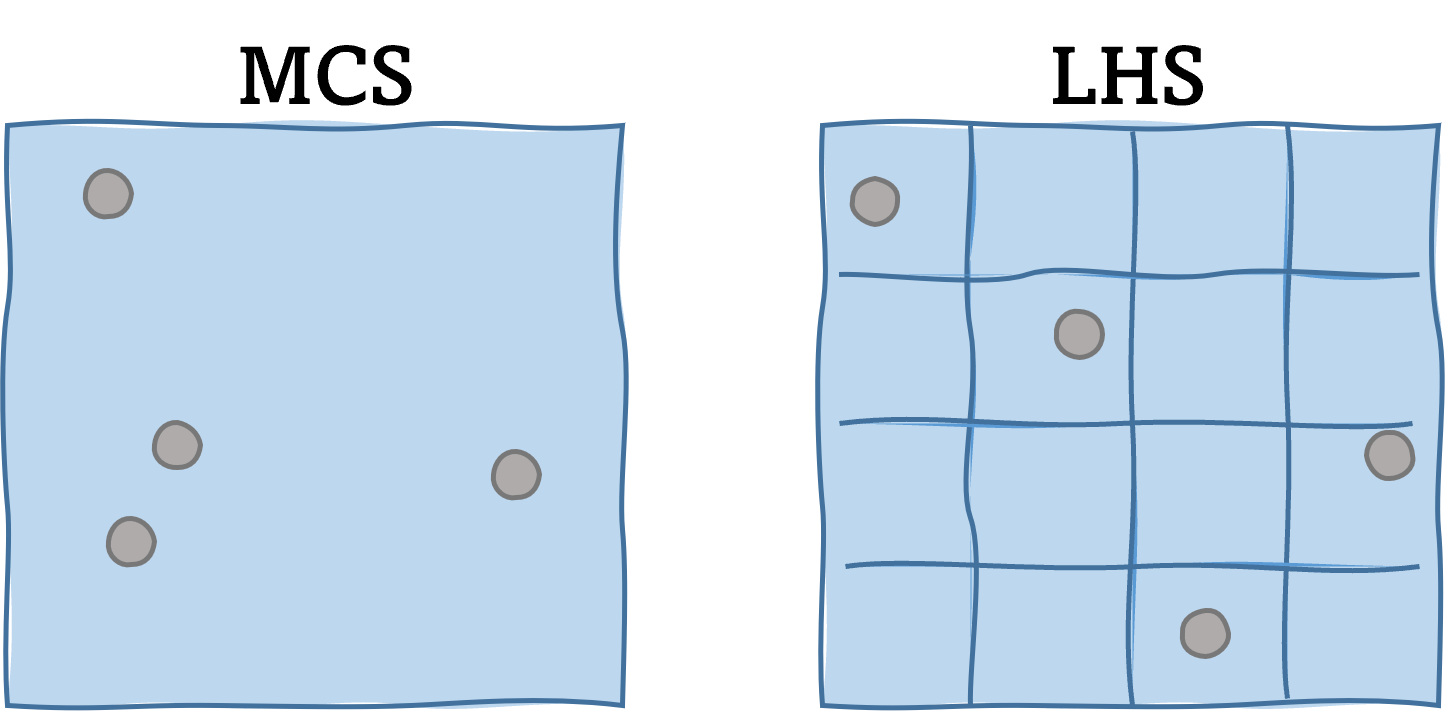
Fig. 3.1.2.1.2 Monte Carlo sampling vs. Latin hypercube sampling¶
Fig. 3.1.2.1.3 shows the input panel corresponding to the Latin hypercube sampling (LHS) scheme. Two input parameters need to be specified: (1) the number of samples of the output to be produced, which is equal to the number of times the model is evaluated, and (2) the seed for the pseudo-random number generator.
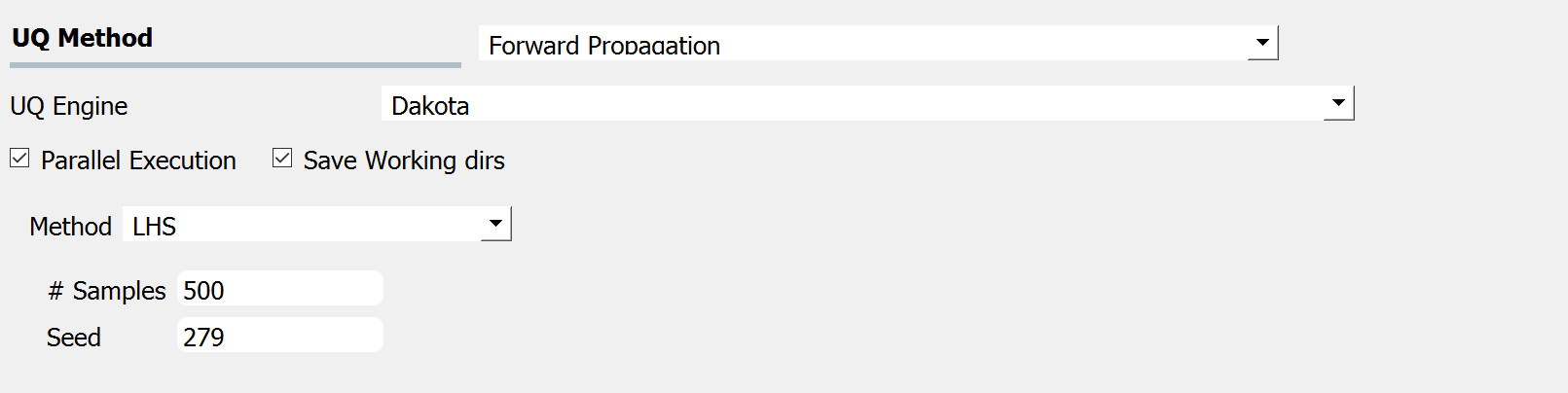
Fig. 3.1.2.1.3 Latin Hypercube Sampling input panel.¶
Gaussian Process Regression (GPR)¶
For the problems in which computationally expensive models are involved, conventional sampling schemes such as LHS and MCS can be extremely time-consuming. In this case, a surrogate model can be constructed based on a smaller number of simulation runs, and then the surrogate model can be used to efficiently generate a larger number of samples replacing the expensive simulations.
Gaussian Process Regression (GPR), also known as Kriging is one of the well-established surrogate techniques, which constructs an approximated response surface based on Gaussian process modeling and covariance matrix optimizations. Fig. 3.1.2.1.4 shows the input panel for the GPR model that consists of training and sampling panels.
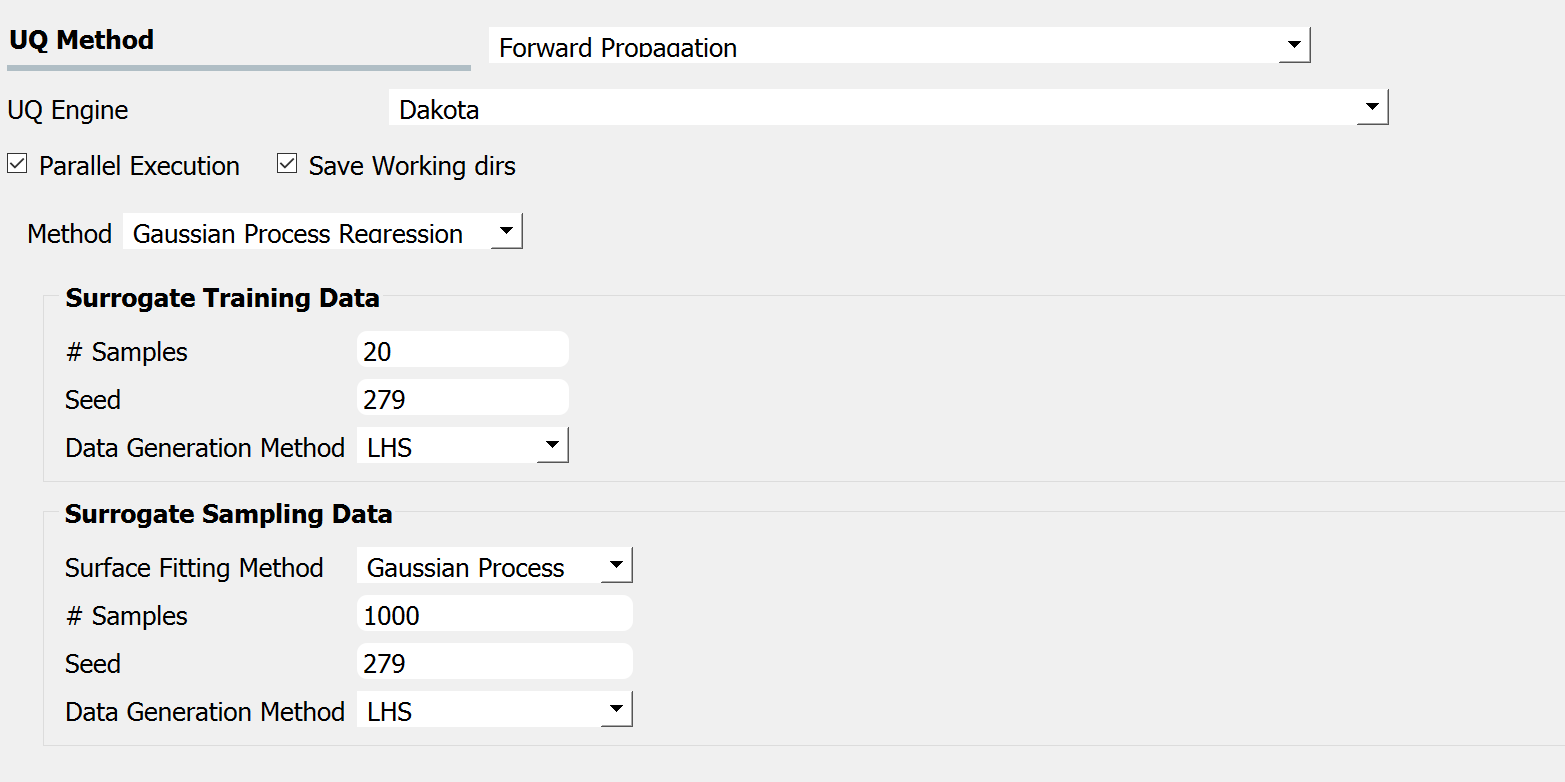
Fig. 3.1.2.1.4 GPR forward propagation input panel.¶
In the Surrogate Training Data panel, the users specify the number of samples of the output of the computationally expensive model to be either Monte Carlo Sampling or Latin Hypercube Sampling to generate sample output values from the computationally expensive model, which, along with the corresponding input values are used to train the surrogate models.
Other surrogate models, different from Gaussian process regression are also available in the drop-down menu titled Surface Fitting Method. All these surrogate models utilize either Monte Carlo Sampling or Latin Hypercube Sampling to generate sample output values, which, along with the corresponding input values are used to train the surrogate models.
Polynomial Chaos Expansion (PCE)¶
Polynomial Chaos Expansion (PCE) is another surrogate model that can replace the expensive simulation model. Similar to the input GPR panel, the input panel for the PCE model shown in Fig. 3.1.2.1.5 consists of training and sampling parts. The input parameters in the surrogate training data set specify the dataset used for training the surrogate model, while the parameters in the surrogate sampling data are related to the samples generated using the surrogate. Extreme care must be taken in specifying the parameters of the training dataset to result in an accurate approximation.
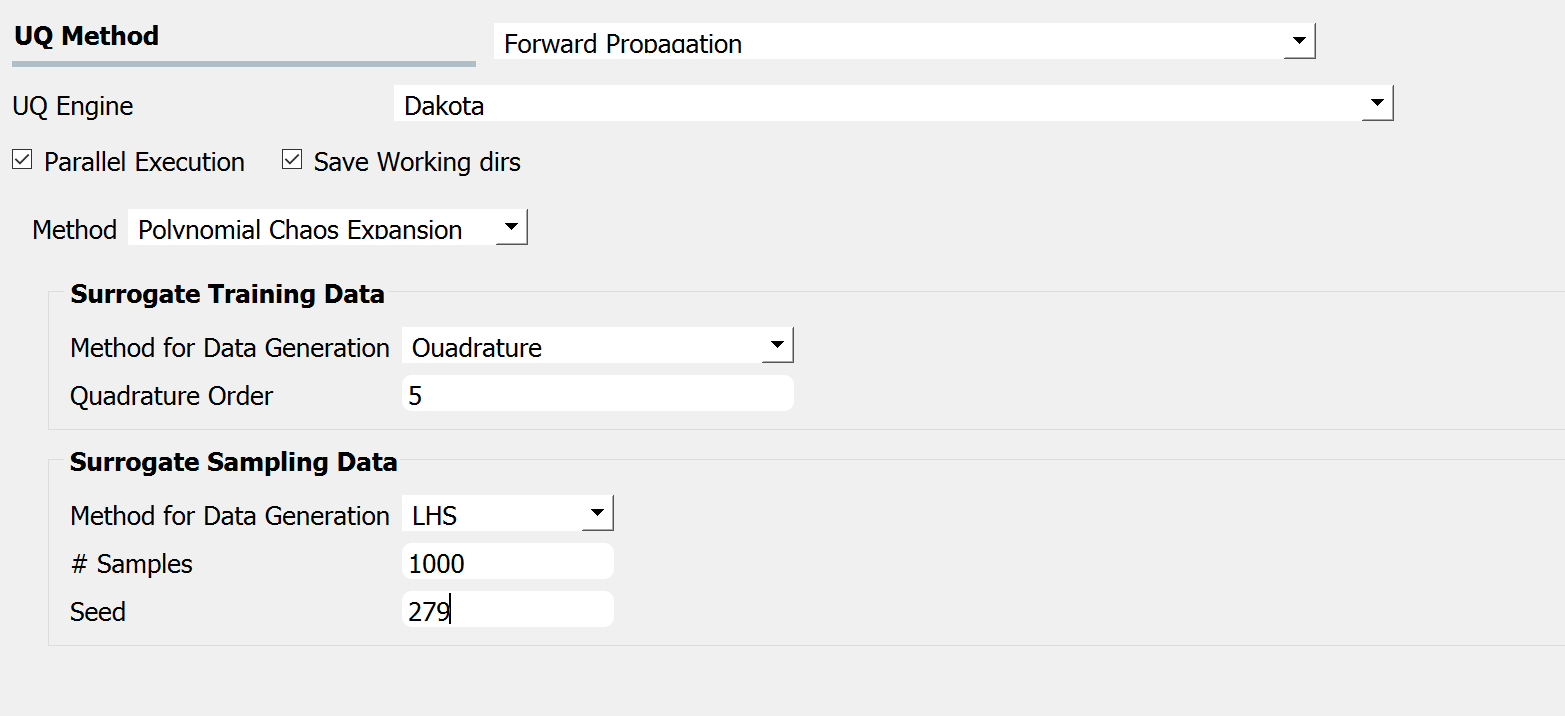
Fig. 3.1.2.1.5 PCE forward propagation input panel.¶
If the user is not familiar with the training parameters of the surrogates, it is recommended to refrain from using the surrogates (PCE in particular) and to instead use conventional sampling approaches such as MCS and LHS, despite a higher computational cost.