4.6. PLoM Surrogate Model
One essential step in seismic structural performance assessment is evaluating structural responses under earthquake ground motion inputs. The typical workflow is demonstrated in Example 4.3. The trade-off between computational efficiency and accuracy is one of the major challenges in problems that require a large number of time history analyses (e.g., risk analysis, and structural optimization). One possible solution is using surrogate models (e.g., response surface, kriging). The surrogate models are first trained for interested responses given a set of relatively expensive simulations. The resulting models can then be applied to predict new realizations more efficiently.
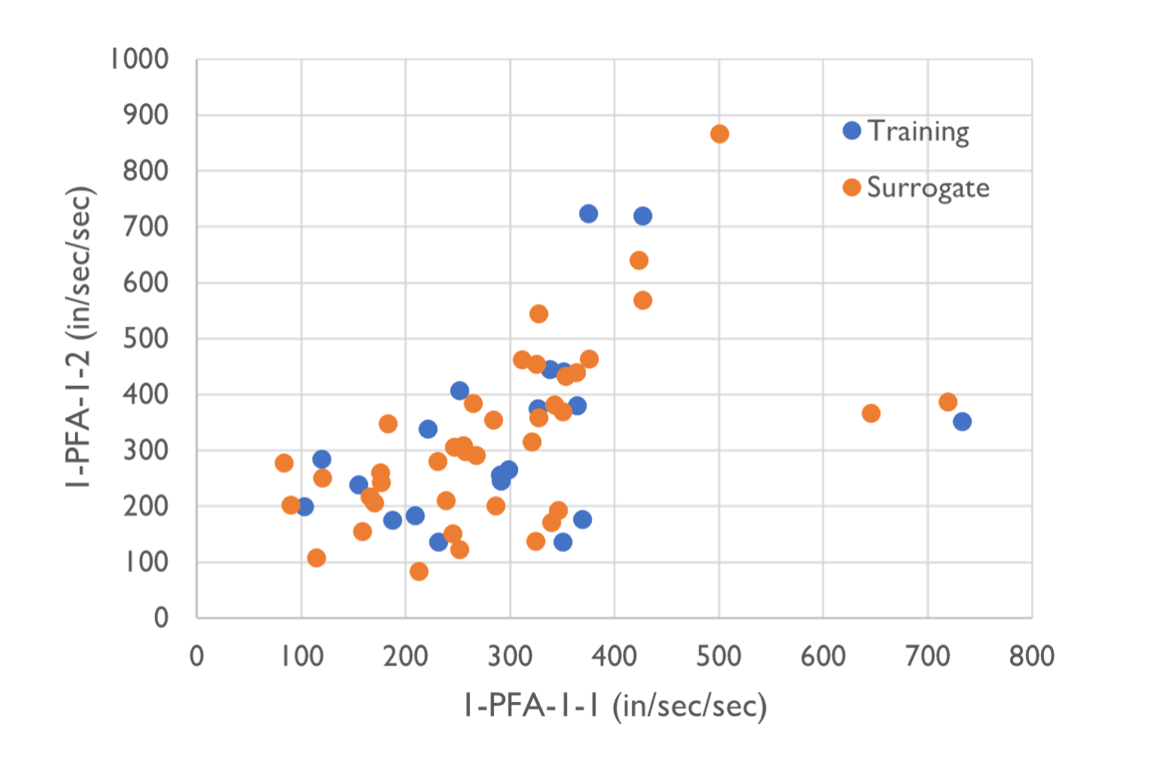
Fig. 4.6.1 Samples generated from the physical simulation model (blue) and the surrogate model (orange)
This example demonstrates using a novel method, Probabilistic Learning on Manifolds (PLoM) [Soize2016], to develop surrogate models for structural responses under earthquake ground motion inputs.
4.6.1. Configure UQ Engine
Navigate to the UQ tab in the left menu. In this panel, select the SimCenterUQ as the UQ Engine. In the SimCenterUQ Method Category, select the PLoM Model method. There are two options for defining a training dataset, Import Data File and Sampling and Simulation. We start with Sampling and Simulation here while the former will be introduced later. LHS is used as the sampling method with 20 samples (corresponding to the 20 ground motions in the run). And we would like to generate 40 new realizations from the 20 training samples (i.e., the New Sample Number Ratio is 2).
Activate the Advanced Options and select Affiliate Variable. In the Type options, select Ground Motion Intensity - Intensity Measure Calculation window would be displayed and allow users to add/remove intensity measures to the surrogate models. In this example, we add two intensity measures, Pseudo Spectral Acceleration and SaRatio.

4.6.2. Configure Structural Analysis
Navigate to the SIM tab and select the MDOF as the Building Model Generator. In this example we use a simple nonlinear SDOF model (yield displacement is 0.01 inch and hardening ratio is 0.1).
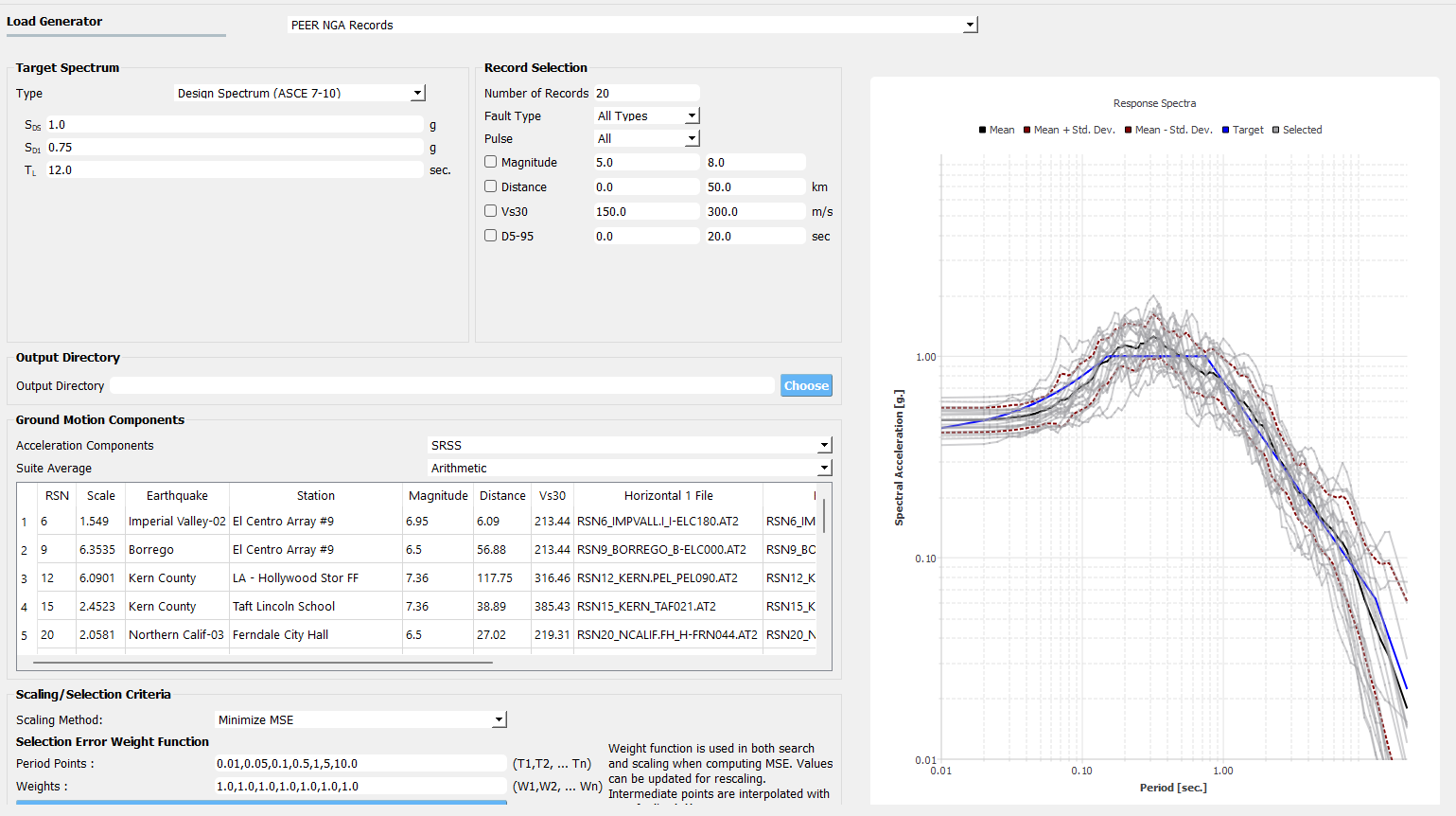
Navigate to the EVT tab and select the PEER NGA Records. We select 20 ground motions to match the default Design Spectrum for analyzing the structural responses under earthquake inputs.
For the FEM and EDP panels, we use default setups to analyze the structural model and record the standard earthquake EDPs, i.e., peak displacement, drift ratio, and acceleration demands.
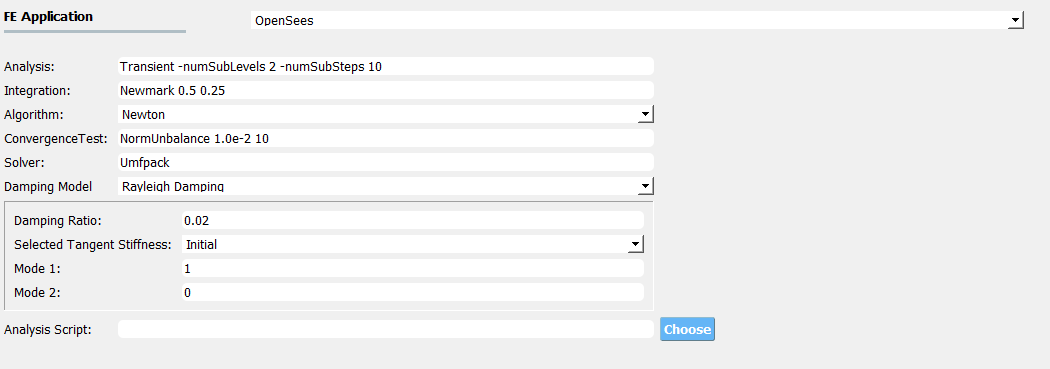

4.6.3. Run the analysis and post-process results
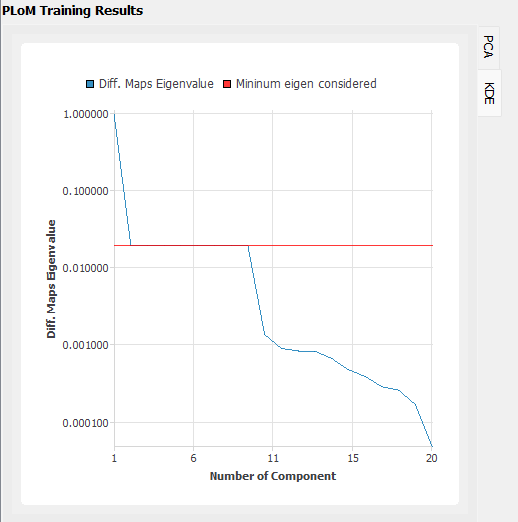
Next click on the Run button. This will call the backend application to launch the analysis. When done the RES panel will first arrive at the Summary panel. Two plots are created to summarize the PLoM training results in the panel (i.e., errors in PCA approximation and diffusion-maps eigenvalues) which can be switched around by clicking the PCA and KDE tabs located on the top-right corner of the chart.

One could save the PLoM model by clicking on Save PLoM Model - an HDF-formatted database along with supplemental files will be stored in the user-defined directory. The saved model can be imported for generating new realizations which will be introduced in a second.
One could navigate to the Data Value panel to visualize and save the new realizations.
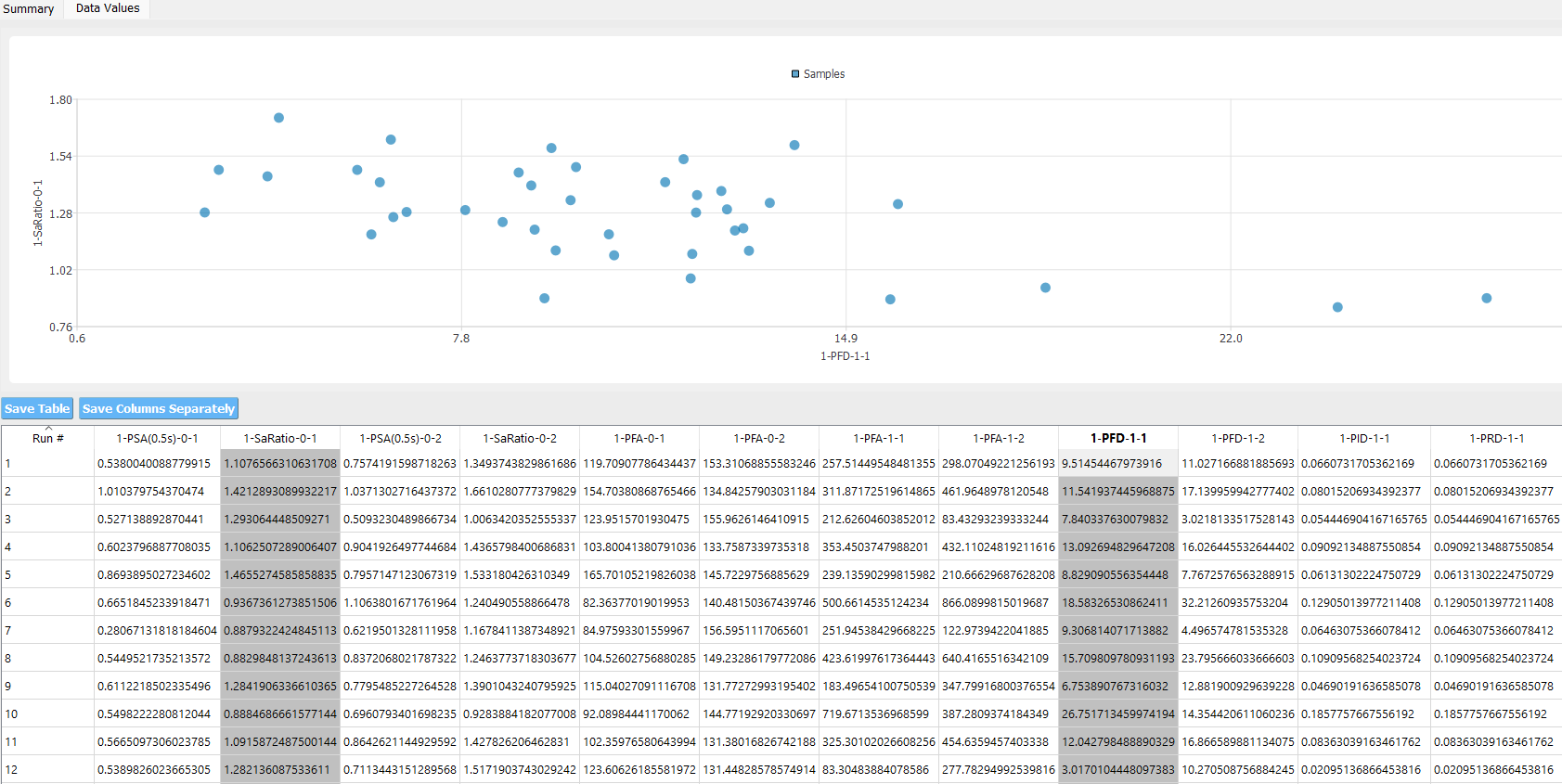
The two figures below compare the data scatter plots between the simulation samples (training set) and surrogate samples (prediction set) which are in good agreement.
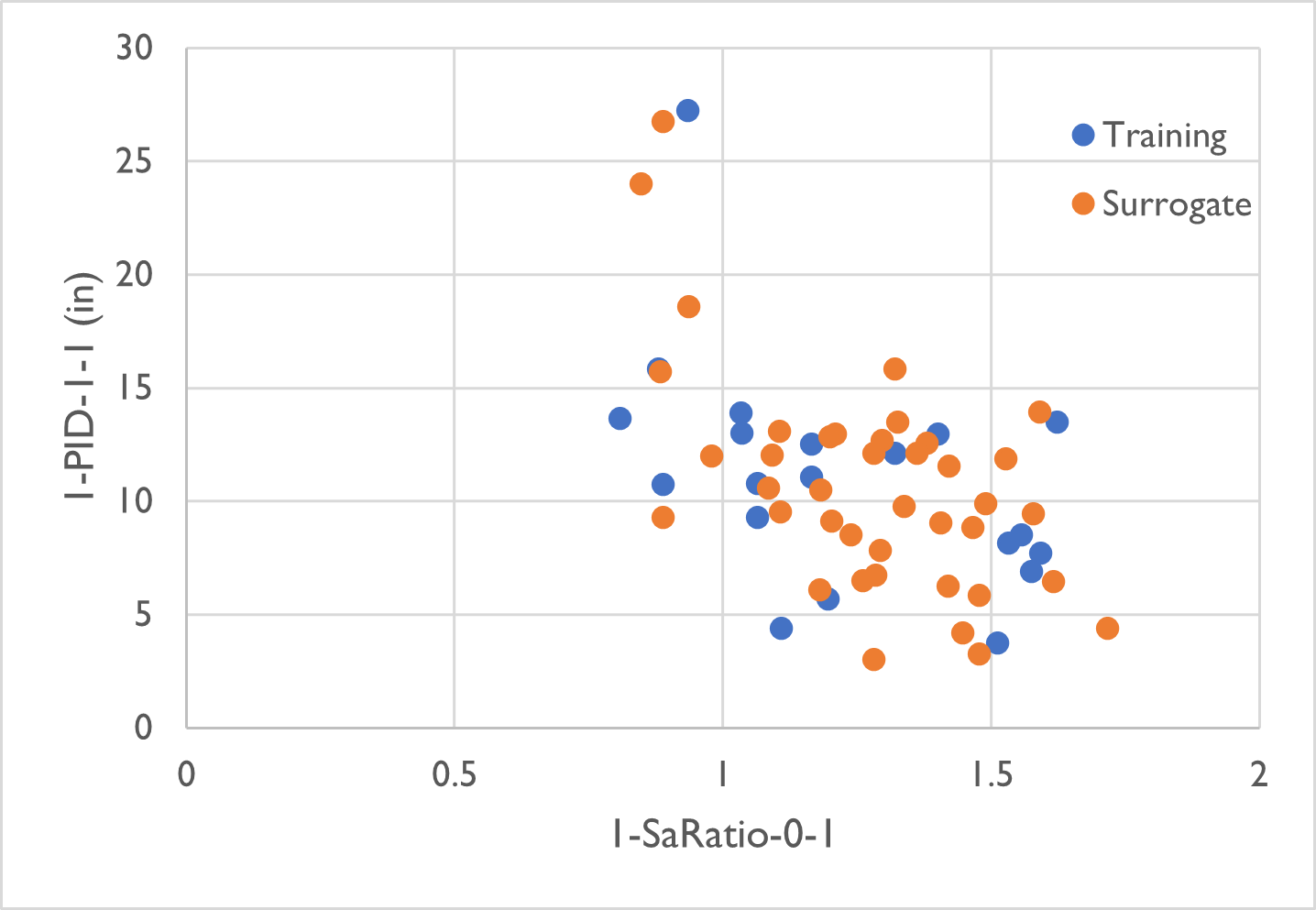
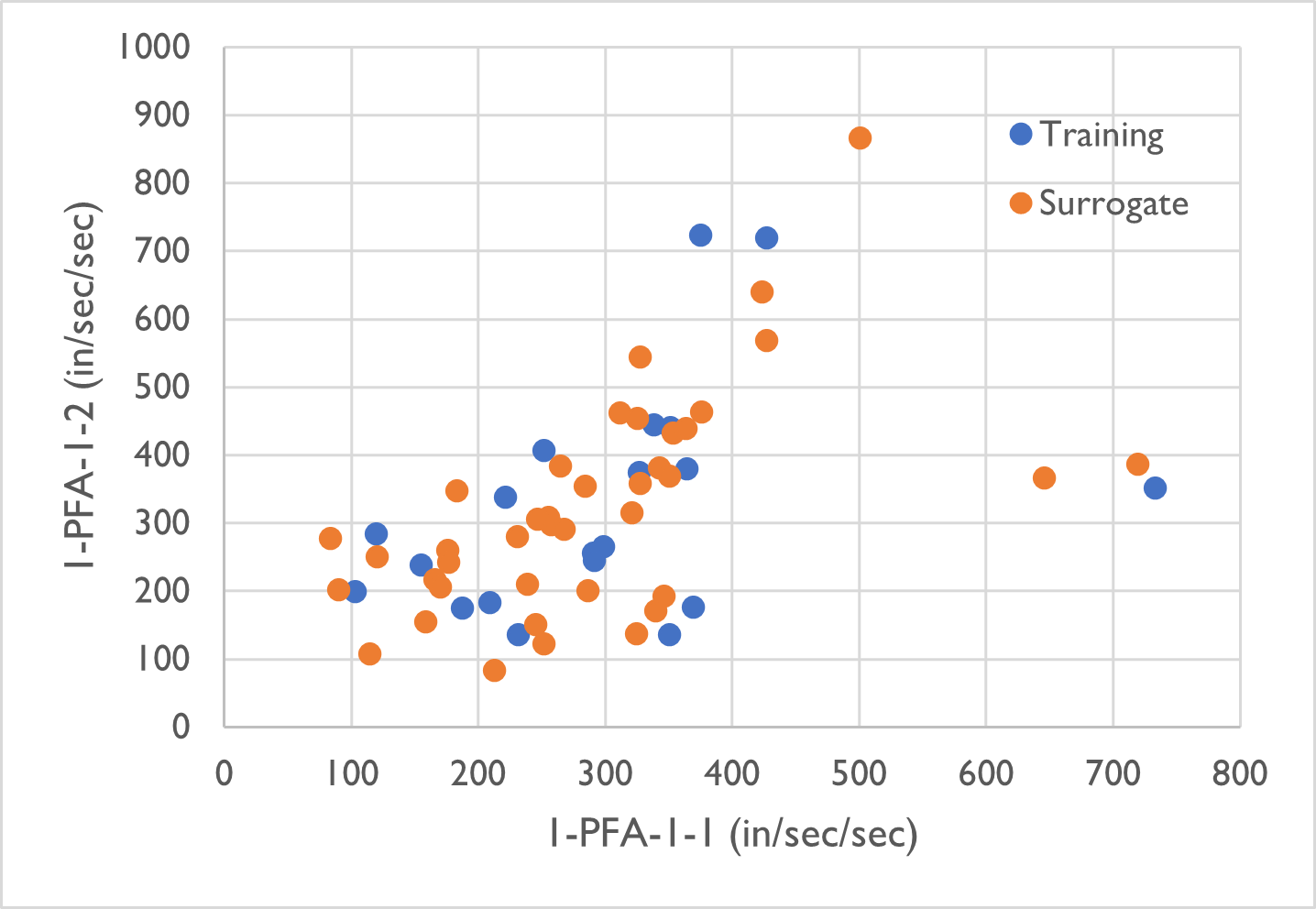
Soize, C., & Ghanem, R. (2016). Data-driven probability concentration and sampling on the manifold. Journal of Computational Physics, 321, 242-258.