To reproduce the result of this example, the user should first click EVT and Select Records, and then click the RUN button. See the below procedure for details.
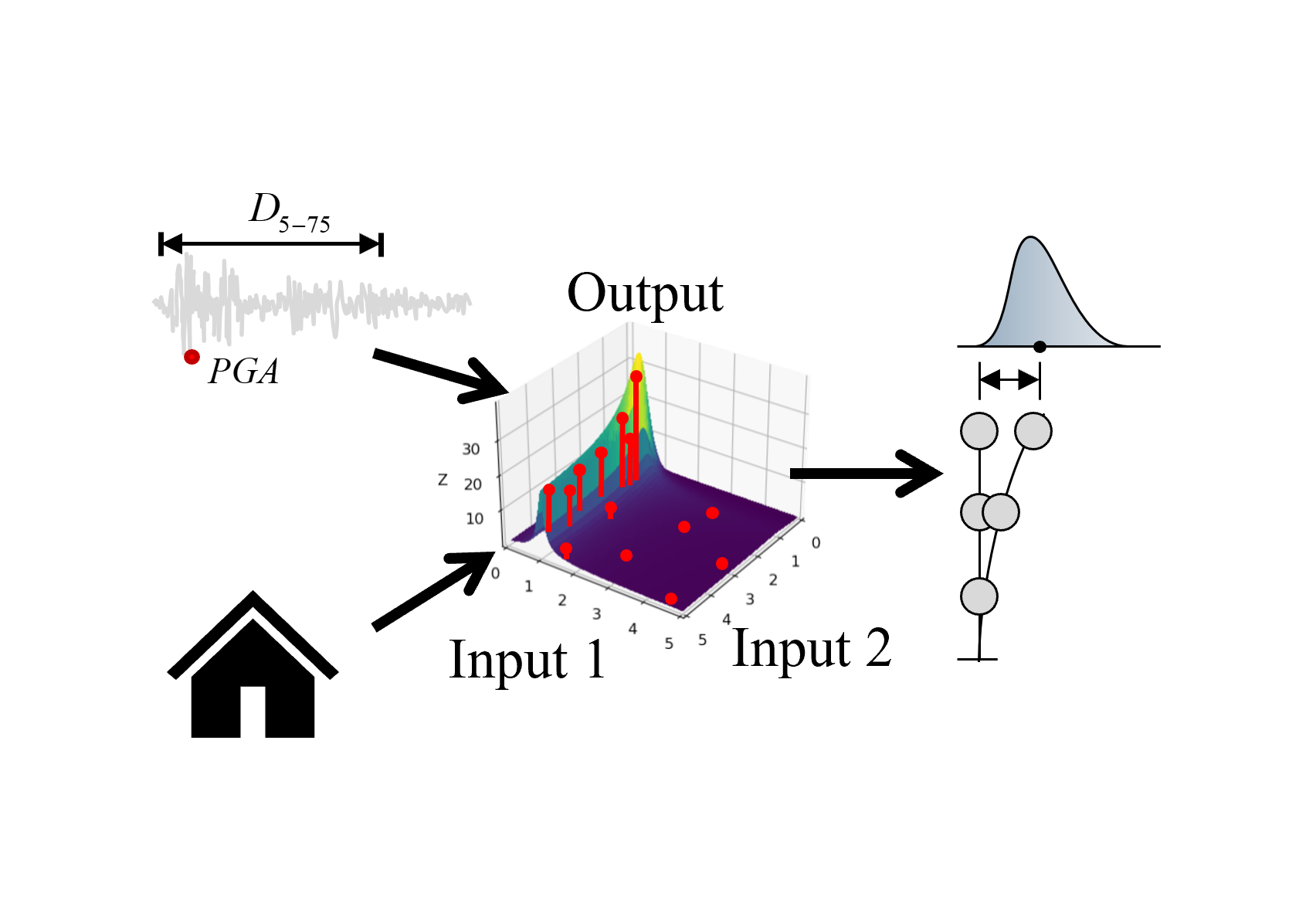
This example shows how to replace structural dynamic simulations using a pre-trained Gaussian process (GP) surrogate model for running forward uncertainty propagation (Monte Carlo Simulation). The ground motions are selected from the PEER NGA database matching the Design Spectrum of ASCE 7-16 standard.
Fig. 4.10.1 Prediction of response statistics using a surrogate model
Important
This examples uses the surrogate model trained in example 09
We will select 30 samples. If recorded ground motions will be used as input excitation, as in this example, the number of ground motions that will be selected in the EVT tab should match the number of samples specified in this tab. This restriction does not apply when a stochastic ground motion generator is used instead of the recorded ground motions.
Example 09 describes how to train the GP surrogate model and save it as .json format.
When the option “Random sample under prediction uncertainty” is selected, the predictions from GP are random realizations that account for both model uncertainty and a portion of uncertainty in the ground motion time histories (i.e. the remaining uncertainty after given intensity measures (IMs)). Alternatively, when the user is interested in only the mean of the response, disregarding all the uncertainties, the user can select “Median (representative) prediction”.
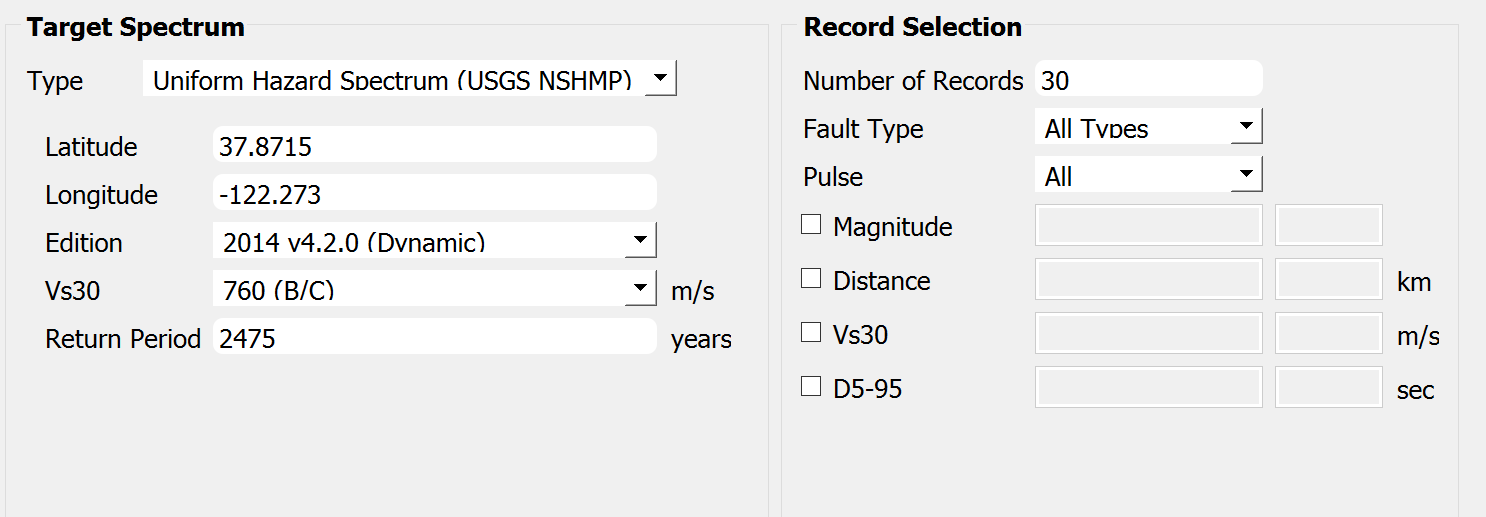
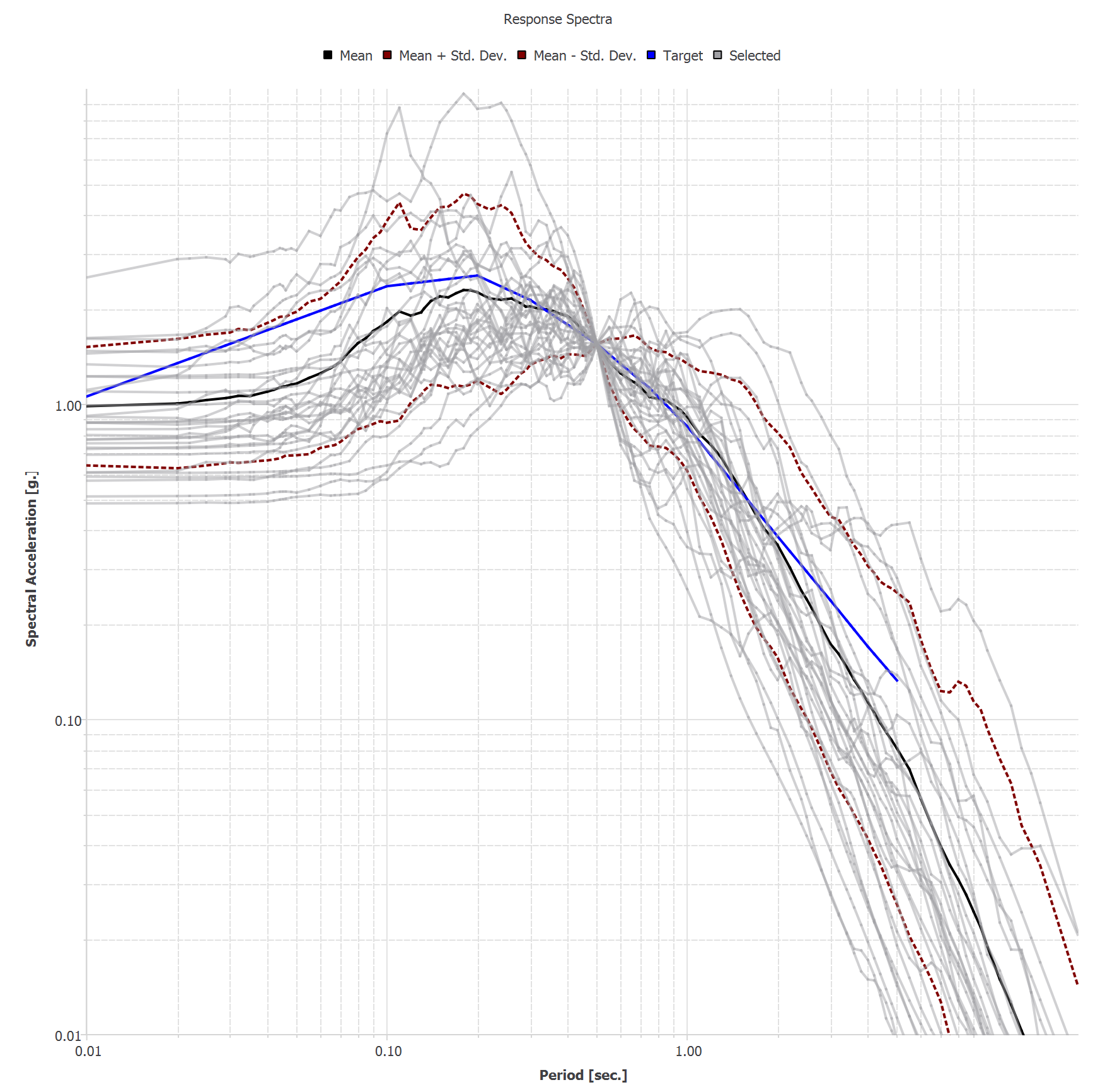
In EVT tab, PEER NGA ground motion records option is selected. Let us consider the site of interest located at (37.8715, -122.273), of which we would like to select ground motions that follow USGS Uniform Hazard Spectrum (2014 v4.2.0) with return period 2475. Vs30 is assumed 760 m/s. Let us select 30 ground motion time histories that match this spectrum by clicking Select records button. The target response spectrum curve and the selected ground motions will be displayed on the right-hand side panel as shown below.
Fig. 4.10.3.2 EVT tab - selected ground motion records on the response spectrum curve
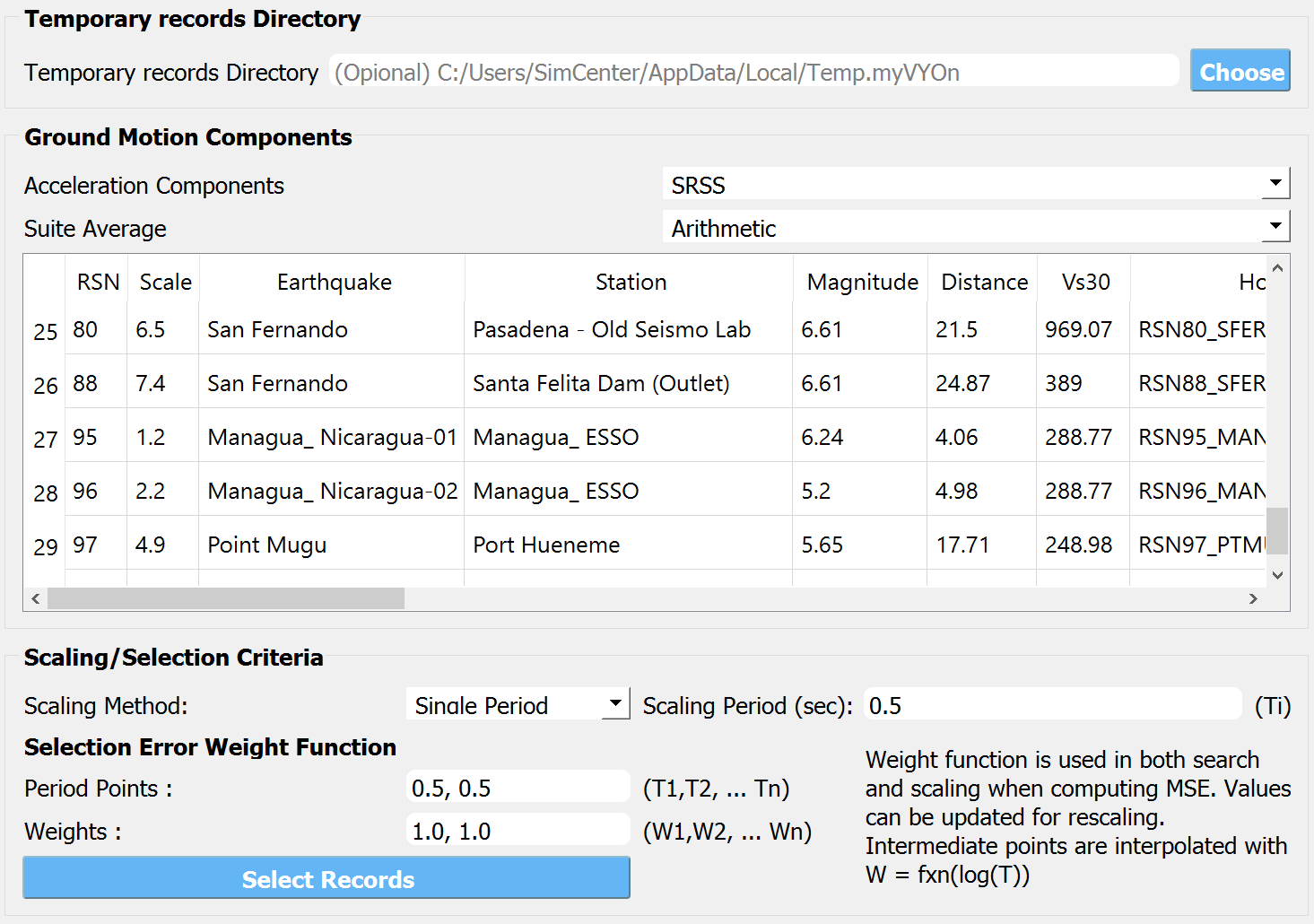
The list of the selected ground motions is shown in the table.
Fig. 4.10.3.3 EVT tab - temporary records directory and scaling options
The actual time histories are saved in the “Temporary Records Directory”.
Warning
Due to copyright issues, PEER imposes a strict limit on the number of records that can be downloaded within a unique time window. The current limit is set at approximately 200 records every two weeks, 400 every month. Please make sure this limit is not exceeded. Otherwise, the analysis will fail.
Temporary Records Directory is where the downloaded ground motion records are stored. It is recommended to specify a directory here instead of using the default temporary directory, in order to reuse the time history data in future analysis.
Acceleration Components option is used to select the directional components to be used in the analysis. For example, if H1 is selected, single-direction ground motion will be excited to the structure.
The RV tab is pre-populated with the random variables that were used to train the surrogate. Change the distribution of the statistical parameters as desired. In this example, the stiffness is assumed to be distributed around 120 with a standard deviation of 5.
Note that the surrogate modeling is essentially based on “interpolation”. Therefore, the distribution of stiffness should not significantly exceed the training bound. If a sampled stiffness value lies outside of the training range, [50, 150] in this example, the prediction from the surrogate model for that sample is likely not reliable.
Click Run button. The analysis may take several minutes. The RES tab will be highlighted when the analysis is completed
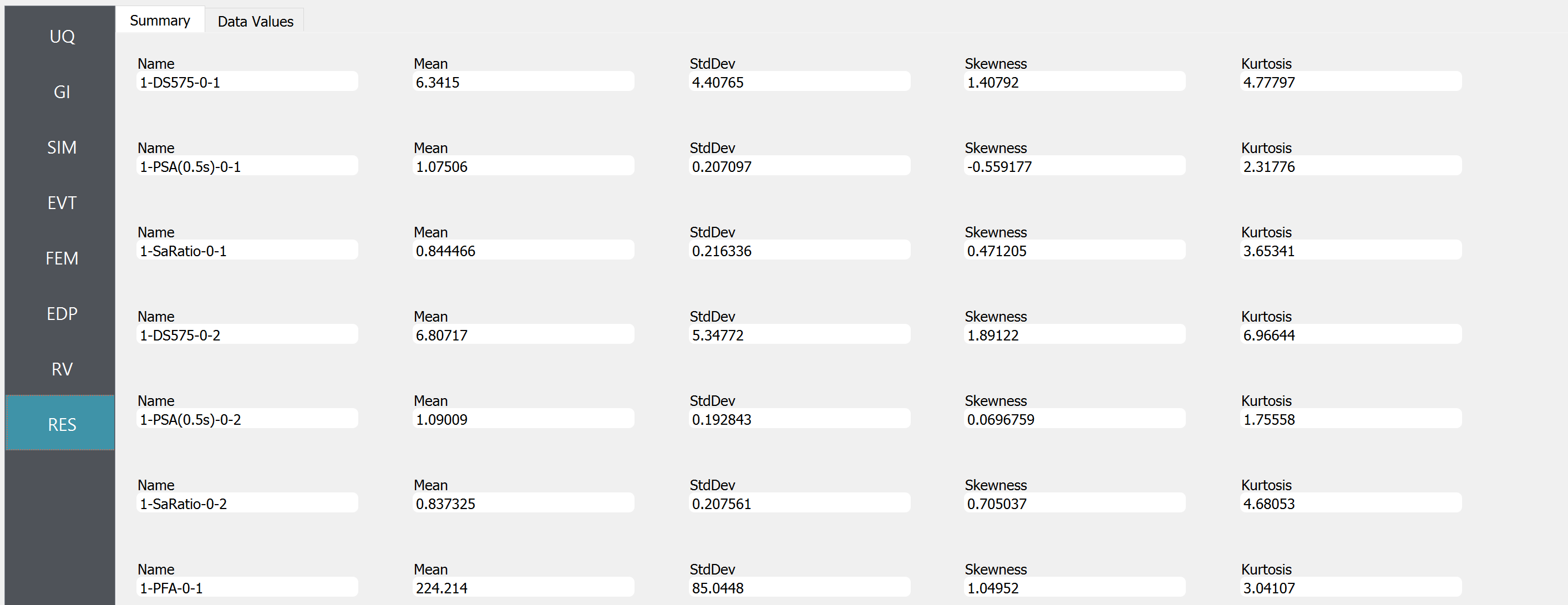
The obtained statistics of responses are shown in the “Summary tab”
Fig. 4.10.5.1 RES tab - summary of response statistics
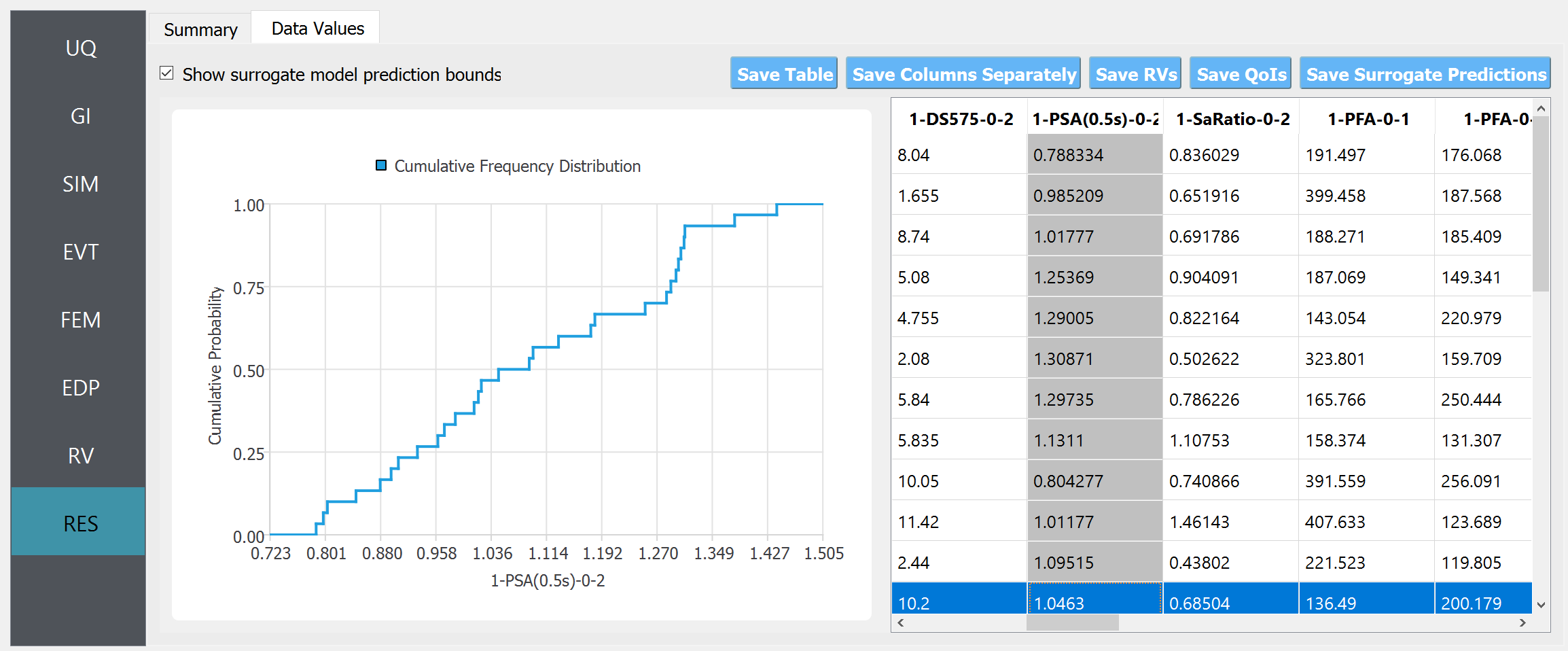
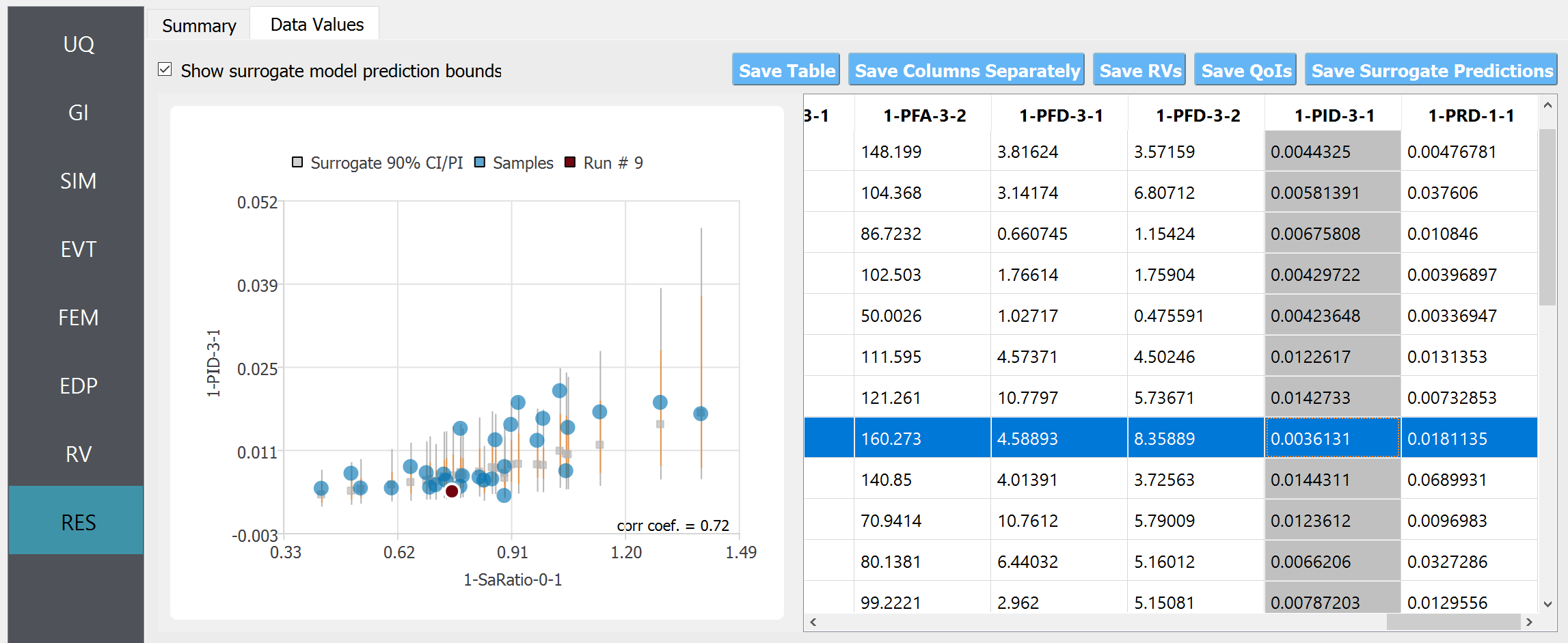
In the “Data Values” tab, one can plot the histogram and cumulative density function (CDF) of the samples, as well as scatter plots between the input and output of surrogate predictions
Fig. 4.10.5.2 RES tab - cumulative density function
Windows: left-click sets the Y axis (ordinate). right-click sets the X axis (abscissa).
MAC: fn-clink, option-click, and command-click all set the Y axis (ordinate). ctrl-click sets the X axis (abscissa).
In the scatter plot, the gray square markers represent the mean prediction from the surrogate, gray bounds denote the 90% prediction interval, orange bounds denote the 90% confidence interval of the mean prediction, and blue dots represent the sample obtained from the surrogate prediction.
Note
The term “90% prediction interval” is the interval in which the exact “response”, i.e. dynamic simulation output, will fall with 90% probability.
The term “90% confidence interval” is the estimated range of the “mean response”. Therefore, the confidence interval is always tighter than the prediction interval.
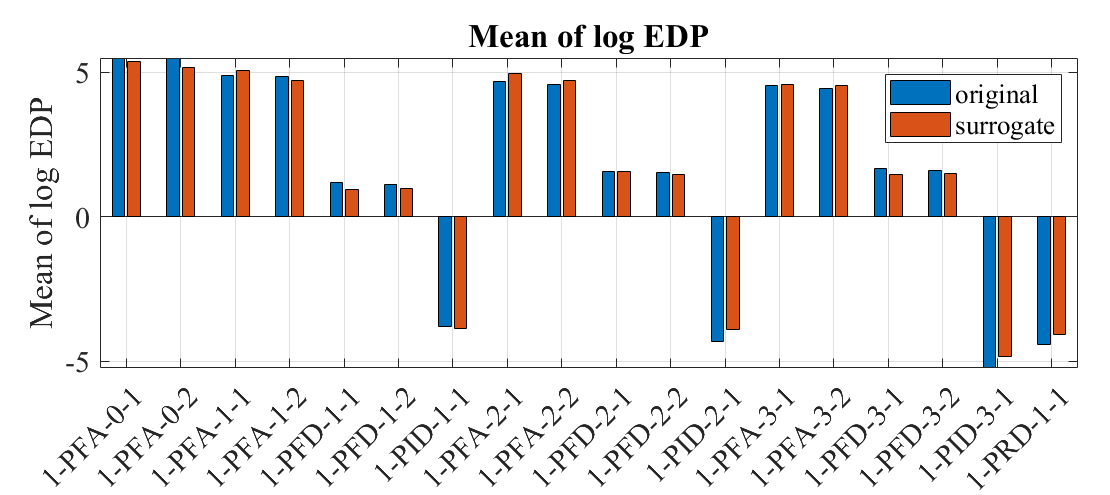
[Verification] Only for verification purposes, an additional forward propagation is performed using the exact simulation model instead of the surrogate model, using the exact same ground motion/structural parameters. For this, UQ, GI, EVT, and RV tabs are kept unchanged, and SIM, FEM, and EDP tabs are modified to replace the surrogate with the original model, i.e. for SIM, FEM, EDP tabs, the exact same configuration used in example 09 was used. Below is a comparison of the obtained mean log-EDPs from 30 samples:
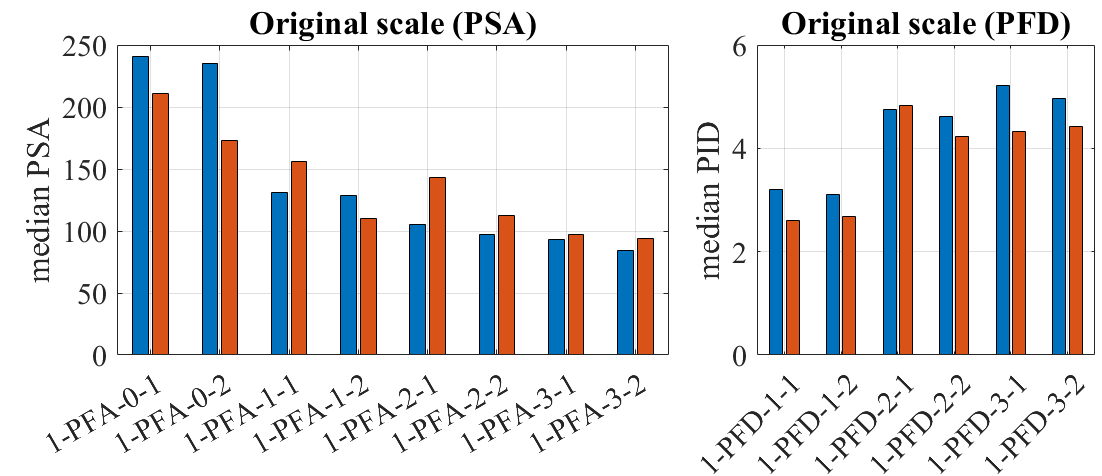
The same comparison in the original scale is shown below.
alt:
The image shows two bar charts side by side. On the left, the chart is titled “Original scale (PSA)” and represents the median PSA values, which range from 0 to 250, for different categories labeled 1-PFA-0-1 to 1-PFA-3-2. The bars are arranged in pairs for each category, with colors alternating between blue and brown. On the right, the chart is titled “Original scale (PFD)” and illustrates the median PFD values, which vary between 0 and 6 for categories labeled 1-PFD-1-1 to 1-PFD-3-2, also with alternating blue and brown bars in pairs. Each pair in both charts likely represents a different condition or measurement within the category.
:align: center
:width: 700
:figclass: align-center
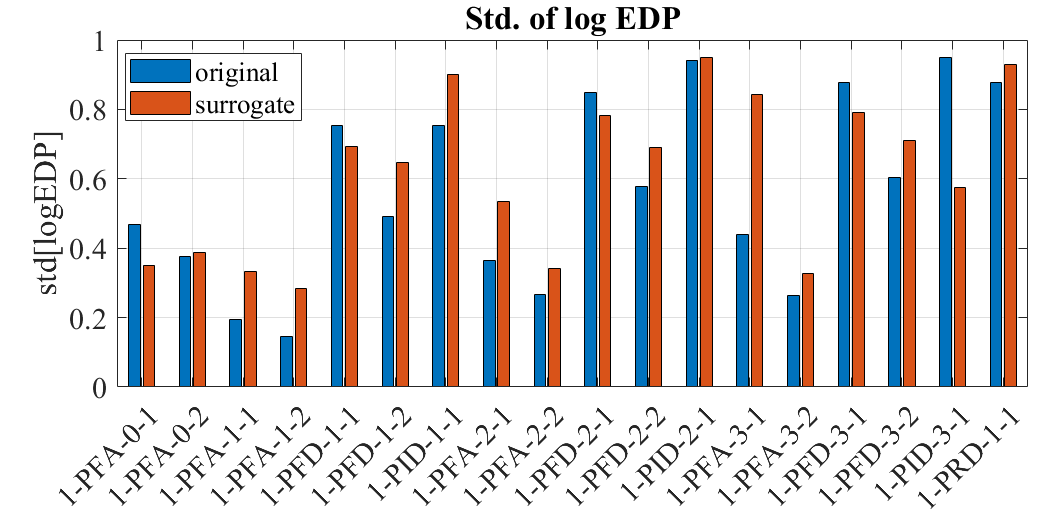
Comparison of log-standard deviation
On the other hand, the log-standard deviation of the EDPs from 30 samples is obtained as below.
Fig. 4.10.5.5 Comparing the standard deviation of log-EDP
The estimated medians of EDPs from the surrogate and the original model show in general good agreement. The standard deviation of the surrogate model is larger partly because of the added uncertainty in the surrogate model approximation. The difference in the statistics may also be attributed to the small sample size of 30.